
Life beyond Distributed Transactions:
an Apostate’s Opinion
跨越分布式事务:背教者的主见
The positions expressed in this paper are personal opinions and do not in any way reflect the positions of my employer Amazon.com.
本文所表达的立场是个人观点,不以任何方式反映我的雇主 Amazon.com 的立场。
摘要(ABSTRACT)
Many decades of work have been invested in the area of distributed transactions including protocols such as 2PC, Paxos, and various approaches to quorum. These protocols provide the application programmer a façade of global serializability. Personally, I have invested a nontrivial portion of my career as a strong advocate for the implementation and use of platforms providing guarantees of global serializability.
在分布式事务领域已有数十年的工作投入,包括 2PC、Paxos 等协议和各种仲裁方法。 这些协议为应用程序员提供了全局可串行化的外部使用方式。 就个人而言,我在职业生涯中投入了很重要的精力,大力倡导实施和使用提供全局可序列化保证的平台。
My experience over the last decade has led me to liken these platforms to the Maginot Line1. In general, application developers simply do not implement large scalable applications assuming distributed transactions. When they attempt to use distributed transactions, the projects founder because the performance costs and fragility make them impractical. Natural selection kicks in...
我在过去十年的经验使我将这些平台比作马奇诺防线。 通常,应用程序开发人员根本不会实现假设分布式事务的大型可扩展应用程序。 当他们尝试使用分布式事务时,项目失败了,因为性能成本和脆弱性使它们不切实际。 自然选择开始…
Instead, applications are built using different techniques which do not provide the same transactional guarantees but still meet the needs of their businesses.
相反,应用程序是使用不同的技术构建的,这些技术不提供相同的事务保证,但仍能满足其业务的需求。
This paper explores and names some of the practical approaches used in the implementations of large-scale mission-critical applications in a world which rejects distributed transactions. We discuss the management of fine-grained pieces of application data which may be repartitioned over time as the application grows. We also discuss the design patterns used in sending messages between these repartitionable pieces of data.
本文探讨并命名了一些在拒绝分布式事务的环境中,用于实现大规模关键任务应用程序的实用方法。 我们讨论了细粒度的应用程序数据的管理,随着应用程序的增长,这些数据可能会随着时间的推移而重新分区。 我们还讨论了在这些可重新分区的数据之间发送消息时使用的设计模式。
The reason for starting this discussion is to raise awareness of new patterns for two reasons. First, it is my belief that this awareness can ease the challenges of people hand-crafting very large scalable applications. Second, by observing the patterns, hopefully the industry can work towards the creation of platforms that make it easier to build these very large applications.
开始这个讨论的原因是为了提高对新模式的认识,原因有两个。 首先,我相信这种意识可以减轻人们手工制作非常大的可扩展应用程序的挑战。 其次,通过观察这些模式,希望行业能够努力创建平台,使构建这些非常大的应用程序变得更加容易。
1. 简介(INTRODUCTION)
Let’s examine some goals for this paper, some assumptions that I am making for this discussion, and then some opinions derived from the assumptions. While I am keenly interested in high availability, this paper will ignore that issue and focus on scalability alone. In particular, we focus on the implications that fall out of assuming we cannot have large-scale distributed transactions.
让我们检查一下本文的一些目标,我为这次讨论所做的一些假设,然后从这些假设中得出一些意见。 虽然我对高可用性非常感兴趣,但本文将忽略该问题并仅关注可伸缩性。 特别是,我们专注于假设我们不能进行大规模分布式事务的影响。
目标(Goals)
This paper has three broad goals:
本文有三个宽泛的目标:
* Discuss Scalable Applications
Many of the requirements for the design of scalable systems are understood implicitly by many application designers who build large systems.
The problem is that the issues, concepts, and abstractions for the interaction of transactions and scalable systems have no names and are not crisply understood. When they get applied, they are inconsistently applied and sometimes come back to bite us. One goal of this paper is to launch a discussion which can increase awareness of these concepts and, hopefully, drive towards a common set of terms and an agreed approach to scalable programs.
This paper attempts to name and formalize some abstractions implicitly in use for years to implement scalable systems.
- 讨论应用程序的扩展性
许多构建大型系统的应用程序设计人员都隐含地理解了设计可扩展系统的许多要求。
问题是事务和可扩展系统交互的问题、概念和抽象没有名称,也没有被清晰地理解。 当它们被应用时,它们的应用不一致,有时会回来咬我们。 本文的一个目标是发起一场讨论,以提高对这些概念的认识,并有望推动一套通用的术语和可扩展程序的商定方法。
本文试图命名和形式化多年来隐式使用的一些抽象,以实现可扩展的系统。
* Think about Almost-Infinite Scaling of Applications
To frame the discussion on scaling, this paper presents an informal thought experiment on the impact of almost-infinite scaling. I assume the number of customers, purchasable entities, orders, shipments, health-care-patients, taxpayers, bank accounts, and all other business concepts manipulated by the application grow significantly larger over time. Typically, the individual things do not get significantly larger; we simply get more and more of them. It really doesn’t matter what resource on the computer is saturated first, the increase in demand will drive us to spread what formerly ran on a small set of machines to run over a larger set of machines...
Almost-infinite scaling is a loose, imprecise, and deliberately amorphous way to motivate the need to be very clear about when and where we can know something fits on one machine and what to do if we cannot ensure it does fit on one machine. Furthermore, we want to scale almost linearly[^3] with the load (both data and computation).
- 考虑应用程序的无限扩展可能性
为了构建关于缩放的讨论,本文提出了一个关于几乎无限缩放的影响的非正式思想实验。 我假设客户、可购买实体、订单、发货、医疗保健患者、纳税人、银行账户以及应用程序操纵的所有其他业务概念的数量随着时间的推移会显着增加。 通常,单个事物不会变得更大; 我们只是得到越来越多的实例。 计算机上的什么资源首先饱和并不重要,需求的增加将促使我们将以前在一小部分机器上运行的东西分散到更大的机器上……
几乎无限缩放是一种松散的、不精确的、故意无定形的方式,它激发了我们需要非常清楚何时何地可以知道某些东西适合一台机器,以及如果我们不能确保它适合一台机器该怎么办。 此外,我们希望随着负载(数据和计算)可以几乎线性扩展[^3]。
* Describe a Few Common Patterns for Scalable Apps.
What are the impacts of almost-infinite scaling on the business logic? I am asserting that scaling implies using a new abstraction called an “entity” as you write your program. An entity lives on a single machine at a time and the application can only manipulate one entity at a time. A consequence of almost-infinite scaling is that this programmatic abstraction must be exposed to the developer of business logic.
By naming and discussing this as-yet-unnamed concept, it is hoped that we can agree on a consistent programmatic approach and a consistent understanding of the issues involved in building scalable systems.
Furthermore, the use of entities has implications on the messaging patterns used to connect the entities. These lead to the creation of state machines that cope with the message delivery inconsistencies foisted upon the innocent application developer as they attempt to build scalable solutions to business problems.
- 描述可扩展应用程序的一些常见模式
几乎无限扩展对业务逻辑有什么影响? 我断言缩放意味着在编写程序时使用一种称为“实体”的新抽象。 一个实体一次存在于一台机器上,应用程序一次只能操作一个实体。 几乎无限扩展的结果是这种程序化抽象必须暴露给业务逻辑的开发人员。
通过命名和讨论这个尚未命名的概念,希望我们能够就一致性编程方法和对构建可扩展系统所涉及的问题的理解达成一致。
此外,实体的使用对用于连接实体的消息传递模式有影响。 这些导致创建状态机来处理强加给无辜应用程序开发人员的消息传递不一致,因为他们试图为业务问题构建可扩展的解决方案。
假设(Assumptions)
Let’s start out with three assumptions which are asserted and not justified. We simply assume these are true based on experience.
让我们从三个被断言但没有被证明的假设开始。 我们只是根据经验假设这些都是正确的。
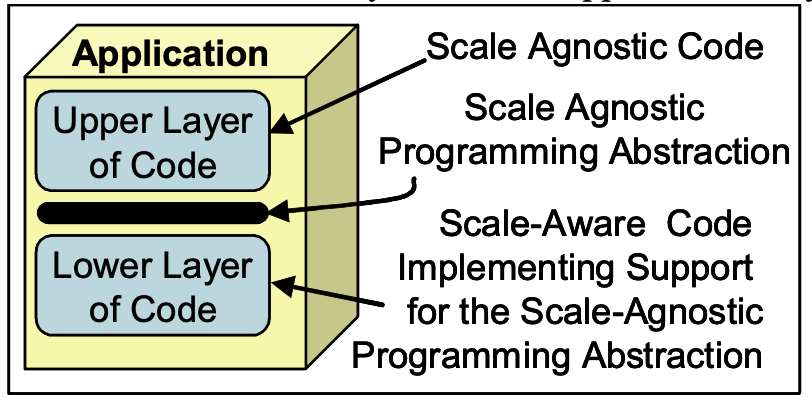
* Layers of the Application and Scale-Agnosticism
Let’s start by presuming (at least) two layers in each scalable application. These layers differ in their perception of scaling. They may have other differences but that is not relevant to this discussion.
The lower layer of the application understands the fact that more computers get added to make the system scale. In addition to other work, it manages the mapping of the upper layer’s code to the physical machines and their locations. The lower layer is scale-aware in that it understands this mapping. We are presuming that the lower layer provides a scale-agnostic programming abstraction to the upper layer[^4].
Using this scale-agnostic programming abstraction, the upper layer of application code is written without worrying about scaling issues. By sticking to the scale-agnostic programming abstraction, we can write application code that is not worried about the changes happening when the application is deployed against ever increasing load.
Over time, the lower layer of these applications may evolve to become new platforms or middleware which simplify the creation of scale-agnostic applications (similar to the past scenarios when CICS and other TP-Monitors evolved to simplify the creation of applications for block-mode terminals).
The focus of this discussion is on the possibilities posed by these nascent scale-agnostic APIs.
- 应用层和规模不可知论
让我们首先假设(至少)每个可扩展应用程序中有两个层。 这些层对缩放的感知不同。 他们可能有其他差异,但这与本次讨论无关。
应用程序的较低层了解添加更多计算机以使系统扩展的事实。 除此之外的其他工作,它还管理上层代码到物理机及其位置的映射。 下层是规模感知的,因为它理解这种映射。 我们假设下层为上层提供了与规模无关的编程抽象。
使用这种与规模无关的编程抽象,编写应用程序代码的上层而不用担心规模问题。 通过坚持与规模无关的编程抽象,我们可以编写不担心在部署应用程序以应对不断增加的负载时发生的变化的应用程序代码。
随着时间的推移,这些应用程序的低层可能会演变成新的平台或中间件,从而简化与规模无关的应用程序的创建(类似于过去的场景,即 CICS 和其他 TP-Monitor 演变为简化应用程序创建的模块化终端)。
本次讨论的重点是这些新生的与规模无关的 API 所带来的可能性。
* Scopes of Transactional Serializability
Lots of academic work has been done on the notion of providing transactional serializability across distributed systems. This includes 2PC (two phase commit) which can easily block when nodes are unavailable and other protocols which do not block in the face of node failures such as the Paxos algorithm.
Let’s describe these algorithms as ones which provide global transactional serializability5. Their goal is to allow arbitrary atomic updates across data spread across a set of machines. These algorithms allow updates to exist in a single scope of serializability across this set of machines.
We are going to consider what happens when you simply don’t do this. Real system developers and real systems as we see them deployed today rarely even try to achieve transactional serializability across machines or, if they do, it is within a small number of tightly connected machines functioning as a cluster. Put simply, we aren’t doing transactions across machines except perhaps in the simple case where there is a tight cluster which looks like one machine.
Instead, we assume multiple disjoint scopes of transactional serializability. Consider each computer to be a separate scope of transactional serializability6.
Each data item resides in a single computer or cluster7. Atomic transactions may include any data residing within that single scope of transactional serializability (i.e. within the single computer or cluster). You cannot perform atomic transactions across these disjoint scopes of transactional serializability. That’s what makes them disjoint!
- 事务可串行化的范围
关于跨分布式系统提供事务可串行化的概念已经完成了大量的学术工作。 这包括可以在节点不可用时轻松阻塞的 2PC(两阶段提交)和其他在节点故障时不会阻塞的协议,例如 Paxos 算法。
让我们将这些算法描述为提供全局事务可串行化的算法[^5]。 他们的目标是允许跨一组机器的数据进行任意原子更新。 这些算法允许更新存在于这组机器的单一可串行化范围内。
我们将考虑当您根本不这样做时会发生什么。 真正的系统开发人员和我们今天看到的实际部署的系统很少尝试实现跨机器的事务可串行化,或者,如果他们这样做,它是在作为集群运行的少数紧密连接的机器中实现的。 简而言之,我们不会跨机器进行事务处理,除非在简单的场景下,有一个看起来像一台机器的紧密集群。
相反,我们假设事务可序列化的多个不相交范围。 将每台计算机视为事务可串行化的单独范围[^6].
每个数据项驻留在单个计算机或集群中[^7]。 原子事务可能包括驻留在事务可串行化的单一范围内(即在单个计算机或集群内)的任何数据。 您不能跨这些不相交的事务可串行化范围执行原子事务。 这就是让他们脱节的原因!
* Most Applications Use “At-Least-Once” Messaging
TCP-IP is great if you are a short-lived Unix-style process. But let’s consider the dilemma faced by an application developer whose job is to process a message and modify some data durably represented on disk (either in a SQL database or some other durable store). The message is consumed but not yet acknowledged. The database is updated and then the message is acknowledged. In a failure, this is restarted and the message is processed again.
The dilemma derives from the fact that the message delivery is not directly coupled to the update of the durable data other than through application action. While it is possible to couple the consumption of messages to the update of the durable data, this is not commonly available. The absence of this coupling leads to failure windows in which the message is delivered more than once. The messaging plumbing does this because its only other recourse is to occasionally lose messages (“at-most-once” messaging) and that is even more onerous to deal with[^8].
A consequence of this behavior from the messaging plumbing is that the application must tolerate message retries and the out-of-order arrival of some messages. This paper considers the application patterns arising when business-logic programmers must deal with this burden in almost-infinitely large applications.
- 大多数应用程序使用“至少一次”消息传递
如果是一个短命的 Unix 风格的进程,TCP-IP 就很棒。 但是让我们考虑一下应用程序开发人员面临的困境,他们的工作是处理消息并修改一些持久存储在磁盘上的数据(在 SQL 数据库或其他持久存储中)。 消息已被消费但尚未确认。 更新数据库,然后确认消息。 如果失败,则重新启动并再次处理消息。
困境源于这样一个事实,即消息传递不直接与持久数据的更新耦合,而是通过应用程序操作。 虽然可以将消息的消费与持久数据的更新结合起来,但这并不常见。 缺少这种耦合会导致出现消息被多次传递的”失败窗口”。 消息管道这样做是因为它唯一的其他办法是偶尔丢失消息(“最多一次”消息),而且处理起来更加繁重[^8]。
消息传递管道的这种行为的结果是应用程序必须容忍消息重试和某些消息的无序到达。 本文考虑了当业务逻辑程序员必须在几乎无限大的应用程序中处理这种负担时出现的应用程序模式。
有正当理由的意见(Opinions to Be Justified)
The nice thing about writing a position paper is that you can express wild opinions. Here are a few that we will be arguing in the corpus of this position paper[^9]:
写立场文件的好处是你可以表达狂野的意见。 以下是我们将在本立场文件的语料库中争论的一些内容:
* Scalable Apps Use Uniquely Identified “Entities”
This paper will argue that the upper layer code for each application must manipulate a single collection of data we are calling an entity. There are no restrictions on the size of an entity except that it must live within a single scope of serializability (i.e. one machine or cluster).
Each entity has a unique identifier or key. An entity-key may be of any shape, form, or flavor but it somehow uniquely identifies exactly one entity and the data contained within that entity.
There are no constraints on the representation of the entity. It may be stored as SQL records, XML documents, files, data contained within file systems, as blobs, or anything else that is convenient or appropriate for the app’s needs. One possible representation is as a collection of SQL records (potentially across many tables) whose primary key begins with the entity-key.
Entities represent disjoint sets of data. Each datum resides in exactly one entity. The data of an entity never overlaps the data of another entity.
An application comprises many entities. For example, an “order-processing” application encapsulates many orders. Each order is identified by a unique Order-ID. To be a scalable “order-processing” application, data for one order must be disjoint from the data for other orders.
- 可扩展应用程序使用唯一标识的“实体”
本文将论证每个应用程序的上层代码必须操作的我们称为实体的单个数据集合。 除了它必须存在于单一的可序列化范围内(即一台机器或集群),对实体的大小没有限制.
每个实体都有一个唯一的标识符或键。 实体键可以是任何形状、形式或风格,但它以某种方式唯一标识一个实体以及该实体中包含的数据。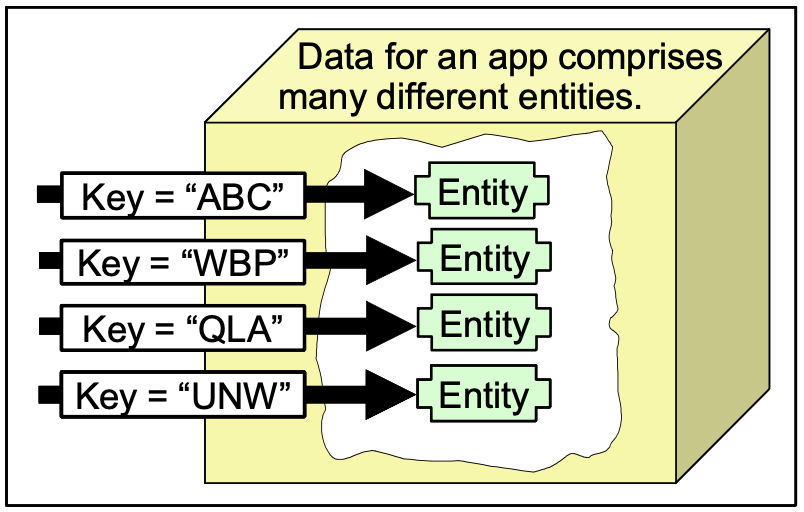
对实体的表示没有任何限制。 它可以存储为 SQL 记录、XML 文档、文件、文件系统中包含的数据、blob 或任何其他方便或适合应用程序需求的东西。 一种可能的表示形式是 SQL 记录的集合(可能跨许多表),其主键以实体键开头。
实体表示不相交的数据集。 每个数据都位于一个实体中。 一个实体的数据永远不会与另一个实体的数据重叠。
一个应用程序包含许多实体。 例如,一个“订单处理”应用程序封装了许多订单。 每个订单都由一个唯一的 Order-ID 标识。 要成为可扩展的“订单处理”应用程序,一个订单的数据必须与其他订单的数据脱节。
* Atomic Transactions Cannot Span Entities
We will argue below why we conclude that atomic transactions cannot span entities. The programmer must always stick to the data contained inside a single entity for each transaction. This restriction is true for entities within the same application and for entities within different applications.
From the programmer’s perspective, the uniquely identified entity is the scope of serializability. This concept has a powerful impact on the behavior of applications designed for scaling. An implication of this we will explore is that alternate indices cannot be kept transactionally consistent when designing for almost-infinite scaling.
- 原子事务不能跨越实体
我们将在下面讨论为什么我们得出结论原子事务不能跨越实体。 对于每个事务,程序员必须始终坚持包含在单个实体中的数据。 此限制适用于同一应用程序内的实体和不同应用程序内的实体。
从程序员的角度来看,唯一标识的实体是可序列化的范围。 这个概念对为扩展而设计的应用程序的行为有很大的影响。 我们将探讨的一个含义是,在为几乎无限扩展设计时,备用索引不能保持事务一致。
* Messages Are Addressed to Entities
Most messaging systems do not consider the partitioning key for the data but rather target a queue which is then consumed by a stateless process.
Standard practice is to include some data in the message that informs the stateless application code where to get the data it needs. This is the entity-key described above. The data for the entity is fetched from some database or other durable store by the application.
A couple of interesting trends are already happening in the industry. First, the size of the set of entities within a single application is growing larger than can fit in a single data-store. Each individual entity fits in a store but the set of them all does not. Increasingly, the stateless application is routing to fetch the entity based upon some partitioning scheme. Second, the fetching and partitioning scheme is being separated into the lower-layers of the application and deliberately isolated from the upper-layers of the application responsible for business logic.
This is effectively driving towards the message destination being the entity key. Both the stateless Unix-style process and the lower-layers of the application are simply part of the implementation of the scale-agnostic API for the business-logic. The upper- layer scale-agnostic business logic simply addresses the message to the entity-key that identifies the durable state known as the entity.
- 消息发送给实体
大多数消息系统不考虑数据的分区键,而是以队列为目标,然后由无状态进程使用。
标准做法是在消息中包含一些数据,通知无状态应用程序代码从何处获取所需数据。 这是上面描述的实体键。 实体的数据由应用程序从某个数据库或其他持久存储中获取。
该行业已经出现了一些有趣的趋势。 首先,单个应用程序中实体集的大小越来越大,无法容纳在单个数据存储中。 每个单独的实体都适合商店,但它们的集合都不适合。 越来越多的无状态应用程序正在路由以基于某些分区方案获取实体。 其次,获取和分区方案被分离到应用程序的低层,并故意与负责业务逻辑的应用程序的上层隔离。
这有效地推动了作为实体键的消息目的地。 无状态的 Unix 风格的流程和应用程序的低层都只是业务逻辑的与规模无关的 API 实现的一部分。 上层与规模无关的业务逻辑只是将消息发送到标识持久状态的实体键,称为实体。
* Entities Manage Per-Partner State (“Activities”)
Scale-agnostic messaging is effectively entity-to-entity messaging. The sending entity (as manifest by its durable state and identified by its entity-key) sends a message which is addressed to another entity. The recipient entity comprises both upper-layer (scale- agnostic) business logic and the durable data representing its state which is stored and accessed by the entity-key.
Recall the assumption that messages are delivered “at- least-once”. This means that the recipient entity must be prepared in its durable state to be assailed with redundant messages that must be ignored. In practice, messages fall into one of two categories: those that affect the state of the recipient entity and those that do not. Messages that do not cause change to the processing entity are easy... They are trivially idempotent. It is those making changes to the recipient that pose design challenges.
To ensure idempotence (i.e. guarantee the processing of retried messages is harmless), the recipient entity is typically designed to remember that the message has been processed. Once it has been, the repeated message will typically generate a new response (or outgoing message) which mimics the behavior of the earlier processed message.
The knowledge of the received messages creates state which is wrapped up on a per-partner basis. The key observation here is that the state gets organized by partner and the partner is an entity.
We are applying the term activity to the state which manages the per-party messaging on each side of this two-party relationship. Each activity lives is exactly one entity. An entity will have an activity for each partner entity from which it receives messages.
In addition to managing message melees, activities are used to manage loosely-coupled agreement. In a world where atomic transactions are not a possibility, tentative operations are used to negotiate a shared outcome. These are performed between entities and are managed by activities.
This paper is not asserting that activities can solve the well known challenges to reaching agreement described so thoroughly in workflow discussions. We are, however, pointing out that almost-infinite scaling leads to surprisingly fine-grained workflow-style solutions. The participants are entities and each entity manages its workflow using specific knowledge about the other entities involved. That two-party knowledge maintained inside an entity is what we call an activity.
Examples of activities are sometimes subtle. An order application will send messages to the shipping application and include the shipping-id and the sending order-id. The message-type may be used to stimulate the state changes in the shipping application to record that the specified order is ready-to-ship. Frequently, implementers don’t design for retries until a bug appears. Rarely but occasionally, the application designers think about and plan the design for activities.
- 实体管理每个合作伙伴的状态(“活动”)
与规模无关的消息传递实际上是实体到实体的消息传递。 发送实体(通过其持久状态显示并由其实体密钥标识)发送一条消息,该消息被寻址到另一个实体。 接收实体包括上层(与规模无关的)业务逻辑和表示其状态的持久数据,这些数据由实体键存储和访问。
回想一下消息“至少一次”传递的假设。 这意味着接收实体必须准备好在其持久状态下受到必须被忽略的冗余消息的攻击。 在实践中,消息属于以下两类之一:影响接收实体状态的和不影响接收实体状态的。 不会导致处理实体发生变化的消息很容易……它们是微弱的幂等的。 正是那些对接受者进行更改的人对设计提出了挑战。
为了确保幂等性(即保证重试消息的处理是无害的),接收实体通常被设计为记住消息已被处理。 一旦它已经被重复,重复的消息通常会生成一个新的响应(或传出消息),它模仿先前处理的消息的行为。
接收到的消息的内容创建了基于每个合作伙伴包装的状态。 这里的关键注意点是,状态由合作伙伴组织,合作伙伴是一个实体。
我们将术语活动应用于管理这种两方关系每一方的每方消息传递的状态。 每个活动精确的存活在一个实体。 一个实体的每个接收消息的伙伴实体都有一个活动。
除了管理消息混乱之外,活动还用于管理松散耦合的协议。 在不可能进行原子事务的世界中,试探性操作用于协商共享结果。 这些操作在实体之间执行并由活动管理。
本文并不是说活动可以解决众所周知的达成共识的挑战,这些挑战在工作流讨论中详尽地描述过。 然而,我们指出,几乎无限的缩放会导致令人惊讶的细粒度工作流式解决方案。 参与者是实体,每个实体使用有关所涉及的其他实体的特定知识来管理其工作流程。 在实体内部维护的两方知识就是我们所说的活动。
活动的例子有时很微妙。 订单应用程序将向运输应用程序发送消息,并包括运输 ID 和发送订单 ID。 消息类型可用于触发运输应用程序中的状态更改,以记录指定的订单已准备好发货。 通常,实现者在出现错误之前不会设计重试。 很少但偶尔,应用程序设计人员会考虑和计划活动的设计。
The remaining part of this paper will examine these assertions in greater depth and propose arguments and explanations for these opinions.
本文的其余部分将更深入地研究这些断言,并为这些观点提出论据和解释。
2. 实体(ENTITIES)
This section examines the nature of entities in greater depth. We first consider the guarantee of atomic transactions within a single entity. Next, we consider the use of a unique key to access the entity and how this can empower the lower-level (scale-aware) part of the application to relocate entities when repartitioning. After this, we consider what may be accessed within a single atomic transaction and, finally, examine the implications of almost-infinite scaling on alternate indices.
本节更深入地研究实体的性质。 我们首先考虑单个实体内原子交易的保证。 接下来,我们考虑使用唯一编码来访问实体,以及这如何使应用程序的较低级别(规模感知)部分在重新分区时能够重新定位实体。 在此之后,我们考虑可以在单个原子事务中访问的内容,最后,检查几乎无限缩放对备用索引的影响。
可序列化的不相交范围(Disjoint Scopes of Serializability)
Each entity is defined as a collection of data with a unique key known to live within a single scope of serializability. Because it lives within a single scope of serializability, we are ensured that we may always do atomic transactions within a single entity.
每个实体都被定义为具有唯一键的数据集合,该键已知存在于单个可序列化范围内。 因为它存在于单一的可序列化范围内,所以可以确保我们总是可以在单个实体中进行原子事务。
It is this aspect that warrants giving the “entity” a different name then an “object”. Objects may or may not share transactional scopes. Entities never share transactional scopes because repartitioning may put them on different machines.
正是这一方面保证了给“实体”一个与“对象”不同的名称。 对象可能共享也可能不共享事务范围。 实体从不共享事务范围,因为重新分区可能会将它们放在不同的机器上。
唯一键控实体(Uniquely Keyed Entities)
Code for the upper layer of an application is naturally designed around collections of data with a unique key. We see customer-ids, social-security-numbers, product- SKUs, and other unique identifiers all the time within applications. They are used as keys to locate the data implementing the applications. This is a natural paradigm. We observe that the boundary of the disjoint scope of serializability (i.e. the “entity”) is always identified by a unique key in practice.
应用程序上层的代码自然是围绕具有唯一键的数据集合设计的。 我们一直在应用程序中看到客户 ID、社会安全号码、产品 SKU 和其他唯一标识符。 它们用作定位实现应用程序的数据的键。 这是一个自然的范式。 我们观察到,可序列化的不相交范围(即“实体”)的边界在实践中总是由唯一的键标识。
重新分区和实体(Repartitioning and Entities)
One of our assumptions is that the emerging upper- layer is scale-agnostic and the lower-layer decides how the deployment evolves as requirements for scale change. This means that the location of a specific entity is likely to change as the deployment evolves. The upper-layer of the application cannot make assumptions about the location of the entity because that would not be scale-agnostic.
我们的假设之一是新兴的上层与规模无关,而下层决定部署如何随着规模变化的需求而演变。 这意味着特定实体的位置可能会随着部署的发展而变化。 应用程序的上层无法对实体的位置做出假设,因为这与规模无关。
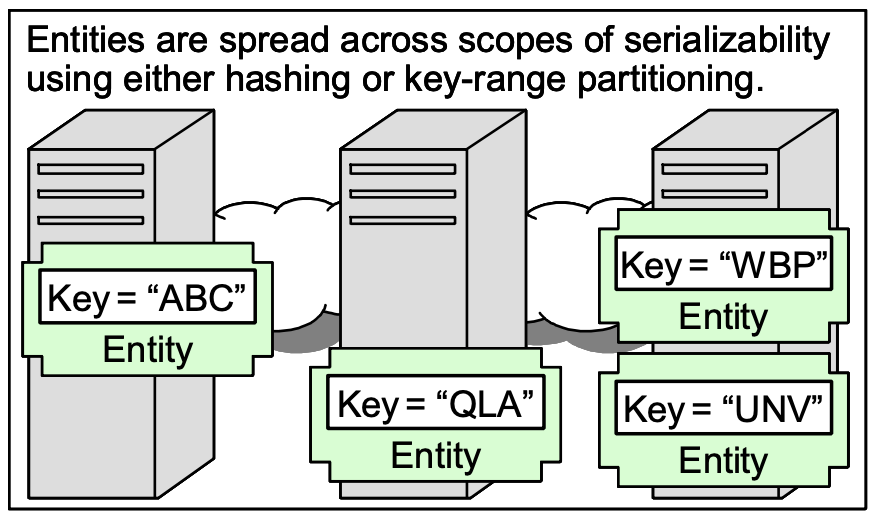
原子事务和实体(Atomic Transactions and Entities)
In scalable systems, you can’t assume transactions for updates across these different entities. Each entity has a unique key and each entity is easily placed into one scope of serializability10. How can you know that two separate entities are guaranteed to be within the same scope of serializability (and, hence, atomically updateable)? You only know when there is a single unique key that unifies both. Now it is really one entity!
在可扩展系统中,您不能假设跨这些不同实体的更新事务。 每个实体都有一个唯一的键,每个实体都可以轻松地放入一个可序列化范围10。 你怎么知道两个独立的实体保证在相同的可序列化范围内(因此,原子可更新)? 您只知道何时有一个唯一的键可以统一两者。 现在它真的是一个实体!
If we use hashing for partitioning by entity-key, there’s no telling when two entities with different keys land on the same box. If we use key-range partitioning for the entity-keys, most of the time the adjacent key- values resides on the same machine but once in a while you will get unlucky and your neighbor will be on another machine. A simple test-case which counts on atomicity with a neighbor in a key-range partitioning will very likely experience that atomicity during the test deployment. Only later when redeployment moves the entities across different scopes of serializability will the latent bug emerge as the updates can no longer be atomic. You can never count on different entity-key-values residing in the same place!
如果我们使用散列来按实体键进行分区,则无法确定两个具有不同键的实体何时落在同一个盒子上。 如果我们对实体键使用键范围分区,大多数情况下相邻的键值都驻留在同一台机器上,但有时你会很不走运,而你的邻居会在另一台机器上。 一个简单的测试用例在键范围分区中依赖于与邻居的原子性,在测试部署期间很可能会遇到这种原子性。 只有稍后当重新部署将实体移动到不同的可序列化范围时,潜在的错误才会出现,因为更新不再是原子的。 您永远不能指望驻留在同一个地方的不同实体键值!
Put more simply, the lower-layer of the application will ensure each entity-key (and its entity) reside on a single machine (or small cluster). Different entities may be anywhere.
更简单地说,应用程序的低层将确保每个实体键(及其实体)驻留在单个机器(或小型集群)上。 不同的实体可能在任何地方。
A scale-agnostic programming abstraction must have the notion of entity as the boundary of atomicity. The understanding of the existence of the entity as a programmatic abstraction, the use of the entity-key, and the clear commitment to assuming a lack of atomicity across entities are essential to providing a scale-agnostic upper layer to the application.
与规模无关的编程抽象必须将实体的概念作为原子性的边界。 将实体的存在理解为编程抽象、实体密钥的使用以及对假设实体之间缺乏原子性的明确承诺对于为应用程序提供与规模无关的上层至关重要。
Large-scale applications implicitly do this in the industry today; we just don’t have a name for the concept of an entity. From an upper-layer app’s perspective, it must assume that the entity is the scope of serializability. Assuming more will break when the deployment changes.
大型应用程序在当今的行业中隐含地做到了这一点; 我们只是没有实体概念的名称。 从上层应用的角度来看,它必须假设实体是可序列化的范围。 假设部署更改时会中断更多。
考虑替代索引(Considering Alternate Indices)
We are accustomed to the ability to address data with multiple keys or indices. For example, sometimes we reference a customer by social security number, sometimes by credit-card number, and sometimes by street address. If we assume extreme amounts of scaling, these indices cannot reside on the same machine or a single large cluster. The data about a single customer cannot be known to reside within a single scope of serializability! The entity itself can reside within a single scope of serializability. The challenge is that the copies of the information used to create an alternate index must be assumed to reside in a different scope of serializability!
我们习惯于使用多个键或索引来处理数据的能力。 例如,有时我们通过社会保险号、有时通过信用卡号、有时通过街道地址来引用客户。 如果我们假设极大的扩展量,这些索引不能驻留在同一台机器或单个大型集群上。 不能知道有关单个客户的数据驻留在单个可序列化范围内! 实体本身可以驻留在单一的可序列化范围内。 挑战在于,必须假定用于创建备用索引的信息副本位于不同的可序列化范围内!
Consider guaranteeing the alternate index resides in the same scope of serializability. When almost-infinite scaling kicks in and the set of entities is smeared across gigantic numbers of machines, the primary index and alternate index information must reside within the same scope of serializability. How do we ensure that? The only way to ensure they both live within the same scope is to begin locating the alternate index using the primary index! That takes us to the same scope of serializability. If we start without the primary index and have to search all of the scopes of serializability, each alternate index lookup must examine an almost-infinite number of scopes as it looks for the match to the alternate key! This will eventually become untenable!
考虑保证备用索引位于相同的可序列化范围内。 当几乎无限的扩展开始并且实体集被涂抹在大量机器上时,主索引和备用索引信息必须位于相同的可序列化范围内。 我们如何确保这一点? 确保它们都位于同一范围内的唯一方法是使用主索引开始定位备用索引! 这将我们带到了相同的可序列化范围。 如果我们在没有主索引的情况下开始并且必须搜索所有可序列化的范围,那么每个备用索引查找必须检查几乎无限数量的范围,因为它寻找与备用键的匹配! 这最终将变得站不住脚!
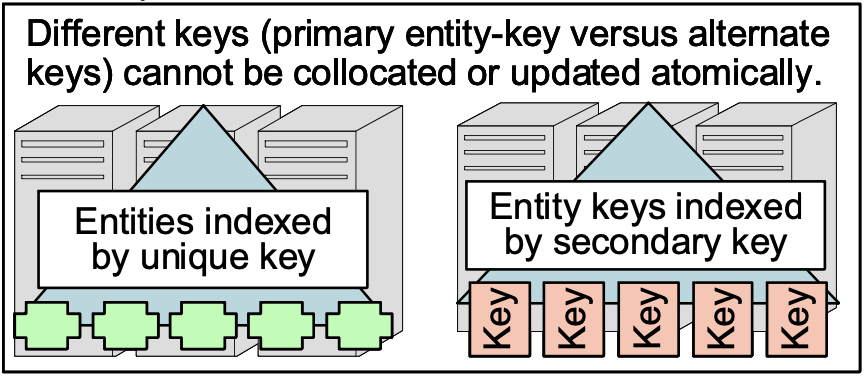
The only logical alternative is to do a two step lookup. First, we lookup the alternate key and that yields the entity-key. Second, we access the entity using the entity- key. This is very much like inside a relational database as it uses two steps to access a record via an alternate key. But our premise of almost-infinite scaling means the two indices (primary and alternate) cannot be known to reside in the same scope of serializability!
唯一合乎逻辑的选择是进行两步查找。 首先,我们查找备用键并产生实体键。 其次,我们使用实体键访问实体。 这非常像在关系数据库中,因为它使用两个步骤通过备用键访问记录。 但是我们几乎无限缩放的前提意味着不能知道两个索引(主索引和备用索引)驻留在相同的可序列化范围内!
The scale-agnostic application program can’t atomically update an entity and its alternate index! The upper-layer scale-agnostic application must be designed to understand that alternate indices may be out of sync with the entity accessed with its primary index (i.e. entity-key).
与规模无关的应用程序无法自动更新实体及其备用索引! 上层与规模无关的应用程序必须设计为了解备用索引可能与其主索引(即实体键)访问的实体不同步。
What in the past has been managed automatically as alternate indices must now be managed manually by the application. Workflow-style updates via asynchronous messaging are all that is left to the almost-infinite scale application. Reading of the data that was previously kept as alternate indices must now be done with an understanding that this is potentially out of sync with the entity implementing the primary representation of the data. The functionality previously implemented as alternate indices is now harder. It is a fact of life in the big cruel world of huge systems!
过去作为备用索引自动管理的内容现在必须由应用程序手动管理。 通过异步消息传递的工作流式更新是几乎无限规模的应用程序所要做的。 以前作为备用索引保存的数据的读取现在必须在理解这可能与实现数据的主要表示的实体不同步的情况下完成。 以前作为备用索引实现的功能现在更难了。 在庞大系统的残酷世界中,这是生活中的事实!
3. 跨实体的消息传递(MESSAGING ACROSS ENTITIES)
In this section, we consider the means to connect independent entities using messages. We examine naming, transactions and messages, look at message delivery semantics, and consider the impact of repartioning the location of entities on these message delivery semantics.
在本节中,我们考虑使用消息连接独立实体的方法。 我们检查命名、事务和消息,查看消息传递语义,并考虑重新划分实体位置对这些消息传递语义的影响。
跨实体通信的消息(Messages to Communicate across Entities)
If you can’t update the data across two entities in the same transaction, you need a mechanism to update the data in different transactions. The connection between the entities is via a message.
如果您无法在同一事务中跨两个实体更新数据,则需要一种机制来更新不同事务中的数据。 实体之间的连接是通过消息。
异步发送事务(Asynchronous with Respect to Sending Transactions)
Since messages are across entities, the data associated with the decision to send the message is in one entity and the destination of the message in another entity. By the definition of an entity, we must assume that they cannot be atomically updated.
由于消息是跨实体的,因此与发送消息的决定相关的数据在一个实体中,而消息的目的地在另一个实体中。 根据实体的定义,我们必须假设它们不能被原子更新。
It would be horribly complex for an application developer to send a message while working on a transaction, have the message sent, and then the transaction abort. This would mean that you have no memory of causing something to happen and yet it does happen! For this reason, transactional enqueuing of messages is de rigueur.
对于应用程序开发人员来说,在处理事务时发送消息、发送消息然后中止事务将是非常复杂的。 这意味着您没有记忆导致某事发生,但它确实发生了! 出于这个原因,消息的事务性排队是必要的。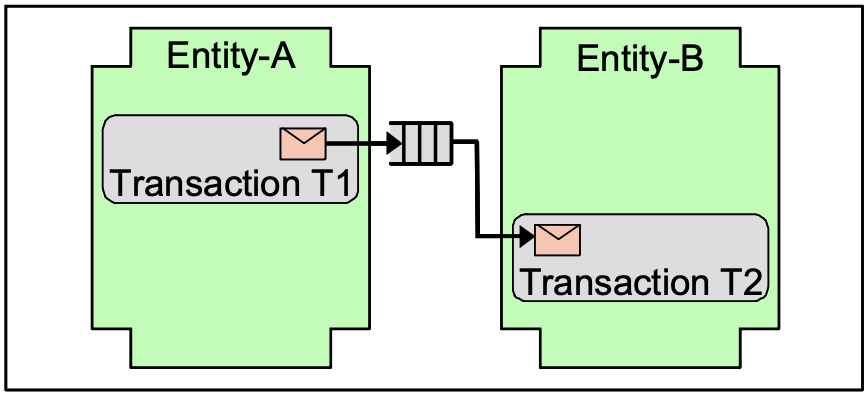
If the message cannot be seen at the destination until after the sending transaction commits, we see the message as asynchronous with respect to the sending transaction. Each entity advances to a new state with a transaction. Messages are the stimuli coming from one transaction and arriving into a new entity causing transactions.
如果在发送事务提交之前无法在目的地看到消息,我们将消息视为相对于发送事务是异步的。 每个实体通过事务进入新状态。 消息是来自一个事务并到达导致事务的新实体的刺激。
命名消息的目的地(Naming the Destination of Messages)
Consider the programming of the scale-agnostic part of an application as one entity wants to send a message to another entity. The location of the destination entity is not known to the scale-agnostic code. The entity-key is.
当一个实体想要向另一个实体发送消息时,考虑对应用程序的与规模无关的部分进行编程。 与规模无关的代码不知道目标实体的位置。 实体键是。
It falls on the scale-aware part of the application to correlate the entity-key to the location of the entity.
它属于应用程序的规模感知部分,用于将实体键与实体的位置相关联。
重新分区和消息传递(Repartitioning and Message Delivery)
When the scale-agnostic part of the application sends a message, the lower-level scale-aware portion hunts down the destination and delivers the message at-least-once.
当应用程序的与规模无关的部分发送消息时,较低级别的规模感知部分会搜索目的地并至少传递一次消息。
As the system scales, entities move. This is commonly called repartitioning. The location of the data for the entity and, hence, the destination for the message may be in flux. Sometimes, messages will chase to the old location only to find out the pesky entity has been sent elsewhere. Now, the message will have to follow.
随着系统扩展,实体移动。 这通常称为重新分区。 实体的数据位置以及消息的目的地可能会不断变化。 有时,消息会追到旧位置,却发现讨厌的实体已被发送到其他地方。 现在,消息将必须遵循。
As entities move, the clarity of a first-in-first-out queue between the sender and the destination is occasionally disrupted. Messages are repeated. Later messages arrive before earlier ones. Life gets messier.
随着实体的移动,发送者和目的地之间的先进先出队列的清晰度偶尔会被破坏。 消息被重复。 较晚的消息在较早的消息之前到达。 生活变得更加混乱。
For these reasons, we see scale-agnostic applications are evolving to support idempotent processing of all application-visible messaging11. This implies reordering in message delivery, too.
由于这些原因,我们看到与规模无关的应用程序正在发展以支持对所有应用程序可见消息的幂等处理11。 这也意味着消息传递中的重新排序。
4 实体、SOA 和对象(ENTITIES, SOA, AND OBJECTS)
This section contrasts the ideas in this paper to those of object orientation and service orientation.
本节将本文中的思想与面向对象和面向服务的思想进行对比。
实体和对象实例(Entities and Object Instances)
One may ask: “How is an entity different than an object instance?” The answer is not black and white. Objects have many forms, some of which are entities and others which are not. There are two important clarifications that must be made to consider an object to be an entity.
有人可能会问:“实体与对象实例有何不同?” 答案不是非黑即白。 对象有多种形式,其中一些是实体,而另一些则不是。 为了将对象视为实体,必须做出两个重要的说明。
First, the data encapsulated by the object must be strictly disjoint from all other data. Second, that disjoint data may never be atomically updated with any other data.
首先,对象封装的数据必须与所有其他数据严格脱节。 其次,不相交的数据可能永远不会用任何其他数据自动更新。
Some object systems have ambiguous encapsulation of database data. To the extent these are not crisp and diligently enforced; these objects are not entities as defined herein. Sometimes, materialized views and alternate indices are used. These won’t last when your system attempts to scale and your objects aren’t entities.
一些对象系统对数据库数据的封装不明确。 在某种程度上,这些不是清晰和努力执行的; 这些对象不是此处定义的实体。 有时,会使用物化视图和备用索引。 当您的系统尝试扩展并且您的对象不是实体时,这些将不会持续。
Many object systems allow transaction scopes to span objects. This programmatic convenience obviates most of the challenges described in this paper. Unfortunately, that doesn’t work under almost-infinite scaling unless your transactionally-coupled objects are always collocated[^12]. To do this, we need to assign them a common key to ensure co-location and then realize the two transactionally-coupled objects are part of the same entity!
许多对象系统允许事务范围跨越对象。 这种编程便利性消除了本文中描述的大部分挑战。 不幸的是,除非您的事务耦合对象总是并置[^12],否则这在几乎无限缩放下不起作用。 为此,我们需要为它们分配一个公共密钥以确保协同定位,然后实现两个事务耦合对象是同一实体的一部分!
Objects are great but they are a different abstraction.
对象很棒,但它们是不同的抽象。
消息vs方法(Messages versus Methods)
Method calls are typically synchronous with respect to the calling thread. They are also synchronous with respect to the calling object’s transaction. While the called object may or may not be atomically coupled with the calling object, the typical method call does not atomically record the intent to invoke a message and guarantee the at-least-once invocation of the called message. Some systems wrap message-sending into a method call and I consider those to be messages, not methods.
方法调用通常相对于调用线程是同步的。 它们对于调用对象的事务也是同步的。 虽然被调用对象可能会或可能不会与调用对象原子耦合,但典型的方法调用不会原子地记录调用消息的意图并保证至少一次调用被调用消息。 一些系统将消息发送包装到方法调用中,我认为这些是消息,而不是方法。
We don’t address the differences in marshalling and binding that usually separate messaging from methods. We simply point out that transactional boundaries mandate asynchrony not usually found with method calls.
我们没有解决通常将消息传递与方法分开的编组和绑定方面的差异。 我们只是指出,事务边界要求方法调用通常不具备异步性。
实体和面向服务的架构(Entities and Service Oriented Architectures)
Everything discussed in this paper is supportive of SOA. Most SOA implementations embrace independent transaction scopes across services.
本文中讨论的所有内容都支持 SOA。 大多数 SOA 实现包含跨服务的独立事务范围。
The major enhancement to SOA presented here is the notion that each service may confront almost-infinite scaling within itself and some observations about what that means. These observations apply across services in a SOA and within those individual services where they are designed to independently scale.
这里提出的对 SOA 的主要增强是每个服务可能在自身内部面临几乎无限扩展的概念以及关于这意味着什么的一些观察。 这些观察适用于 SOA 中的服务以及它们被设计为独立扩展的那些单独的服务。
5. 活动:处理混乱的信息(ACTIVITIES: COPING WITH MESSY MESSAGES)
This section discusses means to cope with the challenges of message retries and reordering. We introduce the notion of an activity as the local information needed to manage a relationship with a partner entity.
本节讨论应对消息重试和重新排序挑战的方法。 我们将活动的概念引入为管理与合作伙伴实体的关系所需的本地信息。
重试和幂等性(Retries and Idempotence)
Since any message ever sent may be delivered multiple times, we need a discipline in the application to cope with repeated messages. While it is possible to build low-level support for the elimination of duplicate messages, in an almost-infinite scaling environment, the low-level support would need to know about entities. The knowledge of which messages have been delivered to the entity must travel with the entity when it moves due to repartitioning. In practice, the low-level management of this knowledge rarely occurs; messages may be delivered more than once.
由于曾经发送的任何消息都可能被多次传递,因此我们需要在应用程序中设置一个规则来处理重复的消息。 虽然可以为消除重复消息构建低级支持,但在几乎无限扩展的环境中,低级支持需要了解实体。 当实体因重新分区而移动时,必须知道哪些消息已传递给实体。 在实践中,这种知识的低级管理很少发生; 消息可能会被多次传递。
Typically, the scale-agnostic (higher-level) portion of the application must implement mechanisms to ensure that the incoming message is idempotent. This is not essential to the nature of the problem. Duplicate elimination could certainly be built into the scale-aware parts of the application. So far, this is not yet available. Hence, we consider what the poor developer of the scale- agnostic application must implement.
通常,应用程序的与规模无关的(更高级别)部分必须实现机制以确保传入消息是幂等的。 这对于问题的性质来说不是必不可少的。 重复消除当然可以内置到应用程序的规模感知部分。 到目前为止,这还不可用。 因此,我们考虑与规模无关的应用程序的可怜的开发人员必须实现什么。
定义实体行为的幂等性(Defining Idempotence of Substantive Behavior)
The processing of a message is idempotent if a subsequent execution of the processing does not perform a substantive change to the entity. This is an amorphous definition which leaves open to the application the specification of what is and what is not substantive.
如果处理的后续执行没有对实体进行实质性更改,则消息的处理是幂等的。 这是一个无定形的定义,它为应用程序留下了关于什么是实质性的和什么不是实质性的规范。
If a message does not change the invoked entity but only reads information, its processing is idempotent. We consider this to be true even if a log record describing the read is written. The log record is not substantive to the behaviour of the entity. The definition of what is and what is not substantive is application specific.[^13]
如果一条消息不改变被调用的实体而只读取信息,那么它的处理是幂等的。 即使写入了描述读取的日志记录,我们也认为这是正确的。 日志记录对实体的行为没有实质意义。 什么是实质性的,什么不是实质性的定义是特定于应用程序的。[^13]
自然幂等(Natural Idempotence)
To accomplish idempotence, it is essential that the message does not cause substantive side-effects. Some messages provoke no substantive work any time they are processed. These are naturally idempotent.
为了实现幂等性,消息不引起实质性副作用是至关重要的。 有些消息在处理的任何时候都不会引起实质性的工作。 这些自然是幂等的。
A message that only reads some data from an entity is naturally idempotent. What if the processing of a message does change the entity but not in a way that is substantive? Those, too, would be naturally idempotent.
只从实体中读取一些数据的消息自然是幂等的。 如果消息的处理确实改变了实体,但没有以实质性的方式改变,该怎么办? 那些也自然是幂等的。
Now, it gets harder. The work implied by some messages actually cause substantive changes. These messages are not naturally idempotent. The application must include mechanisms to ensure that these, too, are idempotent. This means remembering in some fashion that the message has been processed so that subsequent attempts make no substantive change.[^14]
现在,它变得更难了。 一些消息所暗示的工作实际上引起了实质性的变化。 这些消息不是自然幂等的。 应用程序必须包括确保这些机制也是幂等的。 这意味着以某种方式记住该消息已被处理,以便后续尝试不会产生实质性变化。[^14]
It is the processing of messages that are not naturally idempotent that we consider next.
我们接下来考虑的是处理非自然幂等的消息。
将消息作为状态记录(Remembering Messages as State)
To ensure the idempotent processing of messages that are not naturally idempotent, the entity must remember they have been processed. This knowledge is state. The state accumulates as messages are processed.
为了确保对非自然幂等的消息进行幂等处理,实体必须记住它们已被处理。 这种知识就是状态。 状态随着消息的处理而累积。
In addition to remembering that a message has been processed, if a reply is required, the same reply must be returned. After all, we don’t know if the original sender has received the reply or not.
除了记住一条消息已被处理外,如果需要回复,则必须返回相同的回复。 毕竟,我们不知道原始发件人是否收到了回复。
活动:为每个合作伙伴管理状态(Activities: Managing State for Each Partner)
To track relationships and the messages received, each entity within the scale-agnostic application must somehow remember state information about its partners. It must capture this state on a partner by partner basis. Let’s name this state an activity. Each entity may have many activities if it interacts with many other entities. Activities track the interactions with each partner.
为了跟踪关系和收到的消息,与规模无关的应用程序中的每个实体都必须以某种方式记住有关其合作伙伴的状态信息。 它必须逐个合作伙伴捕获此状态。 让我们将此状态命名为活动。 如果每个实体与许多其他实体交互,它可能有许多活动。 活动跟踪与每个合作伙伴的互动。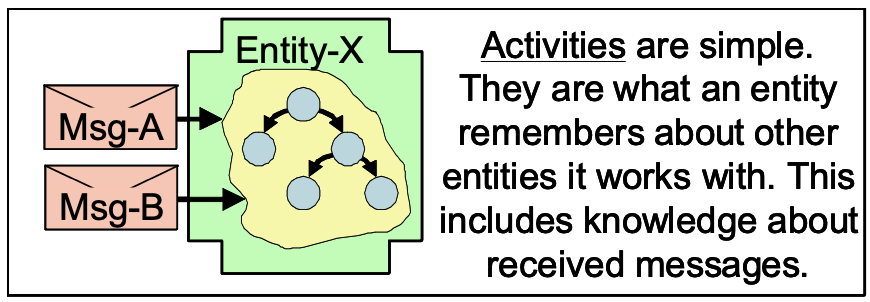
Each entity comprises a set of activities and, perhaps, some other data that spans the activities.
每个实体都包含一组活动,也许还有一些跨越这些活动的其他数据。
Consider the processing of an order comprising many items for purchase. Reserving inventory for shipment of each separate item will be a separate activity. There will be an entity for the order and separate entities for each item managed by the warehouse. Transactions cannot be assumed across these entities. Within the order, each inventory item will be separately managed. The messaging protocol must be separately managed. The per-inventory-item data contained within the order-entity is an activity. While it is not named as such, this pattern frequently exists in large-scale apps.
考虑处理包含许多要购买的物品的订单。 为每个单独的项目的装运保留库存将是一项单独的活动。 将有一个用于订单的实体,并为仓库管理的每个项目提供单独的实体。 不能跨这些实体进行交易。
在订单中,每个库存项目将被单独管理。 消息传递协议必须单独管理。 订单实体中包含的每个库存项目数据是一项活动。 虽然没有这样命名,但这种模式经常存在于大型应用程序中。
In an almost-infinitely scaled application, you need to be very clear about relationships because you can’t just do a query to figure out what is related. Everything must be formally knit together using a web of two-party relationships. The knitting is with the entity-keys. Because the partner is a long ways away, you have to formally manage your understanding of the partners state as new knowledge of the partner arrives. The local information that you know about a distant partner is referred to as an activity.
在一个几乎无限扩展的应用程序中,您需要非常清楚关系,因为您不能仅仅通过查询来找出相关的内容。 一切都必须通过两方关系网络正式结合在一起。 针织是实体键。 因为合作伙伴离我们很远,所以随着对合作伙伴的新知识的到来,您必须正式管理您对合作伙伴状态的理解。 您了解的有关远方伙伴的本地信息称为活动。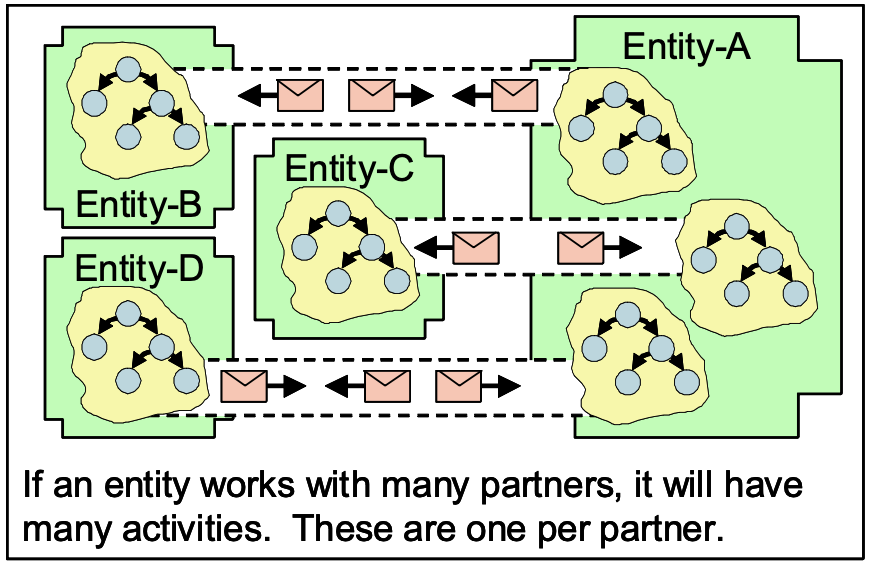
通过活动确保最多一次接受(Ensuring At-Most-Once Acceptance via Activities)
Processing messages that are not naturally idempotent requires ensuring each message is processed at-most-once (i.e. the substantive impact of the message must happen at-most-once). To do this, there must be some unique characteristic of the message that is remembered to ensure it will not be processed more than once.
处理非自然幂等的消息需要确保每条消息最多处理一次(即消息的实质性影响必须最多发生一次)。 为此,必须记住消息的某些独特特征,以确保它不会被多次处理。
The entity must durably remember the transition from a message being OK to process into the state where the message will not have substantive impact.
实体必须持久地记住从消息可以处理到消息不会产生实质性影响的状态的转换。
Typically, an entity will use its activities to implement this state management on a partner by partner basis. This is essential because sometimes an entity supports many different partners and each will pass through a pattern of messages associated with that relationship. By leveraging a per-partner collection of state, the programmer can focus on the per-partner relationship.
通常,实体将使用其活动在逐个合作伙伴的基础上实施这种状态管理。 这是必不可少的,因为有时一个实体支持许多不同的合作伙伴,并且每个合作伙伴都将通过与该关系相关联的消息模式。 通过利用每个合作伙伴的状态集合,程序员可以专注于每个合作伙伴的关系。
The assertion is that by focusing in on the per-partner information, it is easier to build scalable applications. One example is in the implementation of support for idempotent message processing.
断言是,通过关注每个合作伙伴的信息,更容易构建可扩展的应用程序。 一个例子是实现对幂等消息处理的支持。
6. 活动:没有原子性地应对(ACTIVITIES: COPING WITHOUT ATOMICITY)
This section addresses how wildly scalable system make decisions without distributed transactions.
本节讨论了可扩展性极强的系统如何在没有分布式事务的情况下做出决策。
The emphasis of this section is that it is hard work to manage distributed agreement. In addition, though, in an almost-infinitely scalable environment, the representation of uncertainty must be done in a fine-grained fashion that is oriented around per-partner relationships. This data is managed within entities using the notion of an activity.
本节的重点是管理分布式协议是一项艰巨的工作。 此外,尽管如此,在几乎无限可扩展的环境中,不确定性的表示必须以围绕每个合作伙伴关系的细粒度方式完成。 使用活动的概念在实体内管理此数据。
远处的不确定性(Uncertainty at a Distance)
The absence of distributed transactions means we must accept uncertainty as we attempt to come to decisions across different entities. It is unavoidable that decisions across distributed systems involve accepting uncertainty for a while15. When distributed transactions can be used, that uncertainty is manifest in the locks held on data and is managed by the transaction manager.
分布式事务的缺失意味着我们在尝试跨不同实体做出决策时必须接受不确定性。 跨分布式系统的决策不可避免地涉及在一段时间内接受不确定性15。 当可以使用分布式事务时,这种不确定性体现在数据上的锁定中,并由事务管理器管理。
In a system which cannot count on distributed transactions, the management of uncertainty must be implemented in the business logic. The uncertainty of the outcome is held in the business semantics rather than in the record lock. This is simply workflow. Nothing magic, just that we can’t use distributed transaction so we need to use workflow.
在一个不能依赖分布式事务的系统中,不确定性的管理必须在业务逻辑中实现。 结果的不确定性存在于业务语义中,而不是记录锁中。 这只是工作流程。 没什么神奇的,只是我们不能使用分布式事务,所以我们需要使用工作流。
The assumptions that lead us to entities and messages, lead us to the conclusion that the scale-agnostic application must manage uncertainty itself using workflow if it needs to reach agreement across multiple entities.
将我们引向实体和消息的假设使我们得出结论,如果与规模无关的应用程序需要在多个实体之间达成一致,它必须使用工作流自行管理不确定性。
Think about the style of interactions common across businesses. Contracts between businesses include time commitments, cancellation clauses, reserved resources, and much more. The semantics of uncertainty is wrapped up in the behaviour of the business functionality. While more complicated to implement than simply using distributed transactions, it is how the real world works... Again, this is simply an argument for workflow.
想想企业间常见的交互方式。 企业之间的合同包括时间承诺、取消条款、预留资源等等。 不确定性的语义包含在业务功能的行为中。 虽然实现起来比简单地使用分布式事务更复杂,但这就是现实世界的运作方式……
同样,这只是工作流的一个论据。
活动和不确定性管理(Activities and the Management of Uncertainty)
Entities sometimes accept uncertainty as they interact with other entities. This uncertainty must be managed on a partner-by-partner basis and one can visualize that as being reified in the activity state for the partner.
实体有时会在与其他实体交互时接受不确定性。 这种不确定性必须逐个合作伙伴进行管理,并且可以将其可视化为在合作伙伴的活动状态中被具体化。
Many times, uncertainty is represented by relationship. It is necessary to track it by partner. As each partner advances into a new state, the activity tracks this.
很多时候,不确定性是由关系来表示的。 有必要由合作伙伴跟踪。 随着每个合作伙伴进入新状态,活动会对此进行跟踪。
If an ordering system reserves inventory from a warehouse, the warehouse allocates the inventory without knowing if it will be used. That is accepting uncertainty. Later on, the warehouse finds out if the reserved inventory will be needed. This resolves the uncertainty. The warehouse inventory manager must keep relationship data for each order encumbering its items. As it connects items and orders, these will be organized by item. Within each item will be information about outstanding orders against that item. Each of these activities within the item (one per order) manages the uncertainty of the order.
如果订购系统从仓库保留库存,则仓库在不知道是否会使用库存的情况下分配库存。 那就是接受不确定性。 稍后,仓库会查明是否需要预留库存。 这解决了不确定性。
仓库库存经理必须保留每个订单的关系数据,这些订单阻碍了其项目。 当它连接项目和订单时,这些将按项目组织。 每个项目中将包含有关该项目的未完成订单的信息。 项目中的每一项活动(每个订单一项)管理订单的不确定性。
执行暂定业务操作(Performing Tentative Business Operations)
To reach an agreement across entities, one entity has to ask another to accept some uncertainty. This is done by sending a message which requests a commitment but leaves open the possibility of cancellation. This is called a tentative operation and it represented by a message flowing between two entities. At the end of this step, one of the entities agrees to abide by the wishes of the other[^16].
为了跨实体达成协议,一个实体必须要求另一个实体接受一些不确定性。 这是通过发送请求承诺但保留取消可能性的消息来完成的。 这称为试探性操作,它由两个实体之间流动的消息表示。 在此步骤结束时,其中一个实体同意遵守另一个[^16] 的意愿。
暂定操作、确认和取消(Tentative Operations, Confirmation, and Cancellation)
Essential to a tentative operation, is the right to cancel. Sometimes, the entity that requested the tentative operation decides it is not going to proceed forward. That is a cancelling operation. When the right to cancel is released, that is a confirming operation. Every tentative operation eventually confirms or cancels.
一个试探性操作必不可少的,是取消权。 有时,请求试探性操作的实体决定它不会继续进行。 那是取消操作。 当取消权被解除时,即为确认操作。 每个试探性的操作最终都会确认或取消。
When an entity agrees to perform a tentative operation, it agrees to let another entity decide the outcome. This is accepting uncertainty and adds to the general confusion experience by that entity. As confirmations and cancellations arrive, that decreases uncertainty. It is normal to proceed through life with ever increasing and decreasing uncertainty as old problems get resolved and new ones arrive at your lap.
当一个实体同意执行试探性操作时,它同意让另一个实体决定结果。 这是在接受不确定性,并增加了该实体的一般混乱体验。 随着确认和取消的到来,这减少了不确定性。 随着旧问题的解决和新问题的出现,不确定性不断增加和减少的生活是正常的。
Again, this is simply workflow but it is fine-grained workflow with entities as the participants.
同样,这只是简单的工作流,但它是细粒度的工作流,以实体作为参与者。
不确定性和几乎无限缩放(Uncertainty and Almost-Infinite Scaling)
The interesting aspect of this for scaling is the observation that the management of uncertainty usually revolves around two-party agreements. It is frequently the case that multiple two-party agreements happen. Still, these are knit together as a web of fine-grained two-party agreements using entity-keys as the links and activities to track the known state of a distant partner.
扩展的有趣方面是观察到不确定性的管理通常围绕两方协议展开。 经常发生多个两方协议的情况。 尽管如此,它们还是被编织成一个细粒度的两方协议网络,使用实体密钥作为链接和活动来跟踪远方合作伙伴的已知状态。
Consider a house purchase and the relationships with the escrow company. The buyer enters into an agreement of trust with the escrow company. So does the seller, the mortgage company, and all the other parties involved in the transaction. When you go to sign papers to buy a house, you do not know the outcome of the deal. You accept that, until escrow closes, you are uncertain. The only party with control over the decision-making is the escrow company. This is a hub-and-spoke collection of two-party relationships that are used to get a large set of parties to agree without use of distributed transactions.
考虑购房以及与托管公司的关系。 买方与托管公司签订信托协议。 卖方、抵押公司和交易中涉及的所有其他方也是如此。
当你去签文件买房子时,你不知道交易的结果。 您接受这一点,在托管关闭之前,您是不确定的。 唯一可以控制决策的一方是托管公司。
这是两方关系的中心辐射型集合,用于在不使用分布式事务的情况下让大量各方达成一致。
When you consider almost-infinite scaling, it is interesting to think about two-party relationships. By building up from two-party tentative/cancel/confirm (just like traditional workflow) we see the basis for how distributed agreement is achieved. Just as in the escrow company, many entities may participate in an agreement through composition.
当您考虑几乎无限扩展时,考虑两方关系会很有趣。 通过从两方试探/取消/确认(就像传统工作流程一样)构建,我们看到了如何实现分布式协议的基础。 就像在托管公司中一样,许多实体可以通过组合参与协议。
Because the relationships are two-party, the simple concept of an activity as “stuff I remember about that partner” becomes a basis for managing enormous systems. Even when the data is stored in entities and you don’t know where the data lives and must assume it is far away, it can be programmed in a scale-agnostic way.
因为关系是两方的,所以活动的简单概念作为“我记得的关于那个合作伙伴的东西”成为管理庞大系统的基础。 即使数据存储在实体中并且您不知道数据的位置并且必须假设它很远,它也可以以与规模无关的方式进行编程。
Real world almost-infinite scale applications would love the luxury of a global scope of serializability as is promised by two phase commit and other related algorithms. Unfortunately, the fragility of these leads to unacceptable pressure on availability. Instead, the management of the uncertainty of the tentative work is foisted clearly into the hands of the developer of the scale-agnostic application. It must be handled as reserved inventory, allocations against credit lines, and other application specific concepts.
现实世界中几乎无限规模的应用程序会喜欢两阶段提交和其他相关算法所承诺的全局可串行化范围的奢华。 不幸的是,它们的脆弱性导致了不可接受的可用性压力。 相反,暂定工作的不确定性的管理被明确地强加给了与规模无关的应用程序的开发人员手中。 它必须作为保留库存、根据信用额度分配以及其他特定于应用程序的概念来处理。
7. 结论(CONCLUSIONS)
As usual, the computer industry is in flux. One emerging trend is for an application to scale to sizes that do not fit onto a single machine or tightly-coupled set of machines. As we have always seen, specific solutions for a single application emerge first and then general patterns are observed. Based upon these general patterns, new facilities are built empowering easier construction of business logic.
像往常一样,计算机行业处于不断变化之中。 一个新兴趋势是应用程序扩展到不适合单个机器或紧密耦合的机器集的大小。 正如我们一直看到的那样,首先出现针对单个应用程序的特定解决方案,然后观察一般模式。 基于这些通用模式,构建了新的设施,使业务逻辑的构建更加容易。
In the 1970s, many large-scale applications struggled with the difficulties of handling the multiplexing of multiple online terminals while providing business solutions. Emerging patterns of terminal control were captured and some high-end applications evolved into TP- monitors. Eventually, these patterns were repeated in the creation of developed-from-scratch TP-monitors. These platforms allowed the business-logic developers to focus on what they do best: develop business logic.
在 1970 年代,许多大型应用程序在提供业务解决方案的同时面临处理多个在线终端复用的困难。 终端控制的新兴模式被捕获,一些高端应用演变为 TP 监视器。 最终,这些模式在从头开发的 TP 监视器的创建中重复出现。 这些平台允许业务逻辑开发人员专注于他们最擅长的事情:开发业务逻辑。
Today, we see new design pressures foisted onto programmers that simply want to solve business problems. Their realities are taking them into a world of almost-infinite scaling and forcing them into design problems largely unrelated to the real business at hand.
今天,我们看到新的设计压力强加给只想解决业务问题的程序员。 他们的现实正在将他们带入一个几乎无限扩展的世界,并迫使他们陷入与手头实际业务基本无关的设计问题。
Unfortunately, programmers striving to solve business goals like eCommerce, supply-chain-management, financial, and health-care applications increasingly need to think about scaling without distributed transactions. They do this because attempts to use distributed transactions are too fragile and perform poorly.
不幸的是,致力于解决电子商务、供应链管理、金融和医疗保健应用程序等业务目标的程序员越来越需要考虑在没有分布式事务的情况下进行扩展。 他们这样做是因为使用分布式事务的尝试太脆弱并且性能不佳。
We are at a juncture where the patterns for building these applications can be seen but no one is yet applying these patterns consistently. This paper argues that these nascent patterns can be applied more consistently in the hand-crafted development of applications designed for almost-infinite scaling. Furthermore, in a few years we are likely to see the development of new middleware or platforms which provide automated management of these applications and eliminate the scaling challenges for applications developed within a stylized programming paradigm. This is strongly parallel to the emergence of TP-monitors in the 1970s.
我们正处于可以看到构建这些应用程序的模式的关键时刻,但还没有人始终如一地应用这些模式。 本文认为,这些新生模式可以更一致地应用于为几乎无限扩展而设计的应用程序的手工开发。 此外,在几年内,我们可能会看到新的中间件或平台的开发,它们提供对这些应用程序的自动化管理,并消除在程式化编程范式中开发的应用程序的扩展挑战。 这与 1970 年代 TP 监视器的出现非常相似。
In this paper, we have introduced and named a couple of formalisms emerging in large-scale applications: Entities are collections of named (keyed) data which may be atomically updated within the entity but never atomically updated across entities. Activities comprise the collection of state within the entities used to manage messaging relationships with a single partner entity.
在本文中,我们介绍并命名了一些在大规模应用中出现的形式:
实体是命名(键控)数据的集合,这些数据
可以在实体内自动更新,但永远不会
跨实体原子更新。
活动包括在
用于管理与单个合作伙伴实体的消息传递关系的实体。
Workflow to reach decisions, as have been discussed for many years, functions within activities within entities. It is the fine-grained nature of workflow that is surprising as one looks at almost-infinite scaling.
正如多年来所讨论的那样,达成决策的工作流程在实体内的活动中发挥作用。 当人们看到几乎无限的缩放时,令人惊讶的是工作流程的细粒度性质。
It is argued that many applications are implicitly designing with both entities and activities today. They are simply not formalized nor are they consistently used. Where the use is inconsistent, bugs are found and eventually patched. By discussing and consistently using these patterns, better large-scale applications can be built and, as an industry, we can get closer to building solutions that allow business-logic programmers to concentrate on the business-problems rather than the problems of scale.
有人认为,当今许多应用程序都在隐含地设计实体和活动。 它们根本没有正式化,也没有始终如一地使用。 在使用不一致的地方,会发现错误并最终修补。 通过讨论和持续使用这些模式,可以构建更好的大型应用程序,并且作为一个行业,我们可以更接近构建允许业务逻辑程序员专注于业务问题而不是规模问题的解决方案。