
Effective Aggregate Design Part III: Gaining Insight Through Discovery
DDD有效聚合设计,第三部分:通过发现深入理解
Part II discussed how [DDD] aggregates reference other aggregates, and how to leverage eventual consistency to keep separate aggregate instances in harmony. In Part III we'll see how adhering to the rules of aggregate affects the design of a Scrum model. We'll see how the project team rethinks their design again, applying new-found techniques. That effort leads to the discovery of new insights into the model. Their various ideas are tried and then superseded.
第二部分讨论了[DDD]聚合如何引用其他聚合,以及如何借助最终一致性来保持聚合实例的和谐分离。在第三部分我们将会看到遵循聚合规则会如何影响我们的Scrum的模型设计。我们将会看到项目团队如何重新思考他们的设计,应用新学到的技术。这些努力引导我们发现对模型的深入理解。有很多的想法被尝试和替代。
再一次重新思考设计(Rethinking the Design, Again)
After the refactoring iteration that broke up the large cluster Product, the BacklogItem now stands alone as its own aggregate. It reflects the model presented in Figure 7. The team composed a collection of Task instances inside the BacklogItem aggregate. Each BacklogItem has a globally unique identity, its BacklogItemId. All associations to other aggregates are inferred through identities. That means its parent Product, the Release it is scheduled within, and the Sprint to which it is committed, are referenced by identities. It seems fairly small. With the team now jazzed about designing small aggregates, could they possibly overdo it in that direction?
在打破大聚类聚合的重构迭代后,积压项(BacklogItem)现在在它自己的聚合中保持独立。它相应的模型显示在图示7中。团队在积压项(BacklogItem)的聚合中组合了一个集合的任务(Task)实例。每一个积压项(BacklogItem)都有一个全局唯一的标识,即BacklogItemId。所有到其他聚合的关联都通过标识推断。这意味着它的父产品(Product), 它规划到的版本(Release),以及它提交到的冲刺(Sprint),都通过标识引用。它看起来相当的小。如果团队现在很喜欢设计小的聚合,那么会不会可能在这个方向上过分运用?
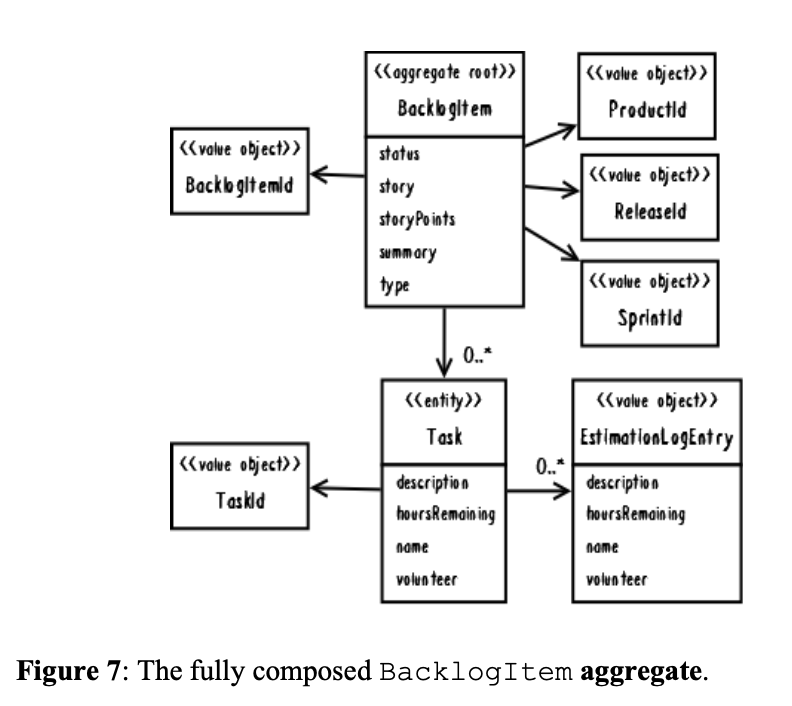
Despite the good feeling coming out of that previous iteration, there is still some concern. For example, the story attribute allows for a good deal of text. Teams developing agile stories won't write lengthy prose. Even so, there is an optional editor component that supports writing rich use case definitions. Those could be many thousands of bytes. It's worth considering the possible overhead.
尽管从上面的迭代中大家感觉良好,但这里还是有一些担心。例如,store属性允许处理好文本。开发敏捷故事的团队不想写长长的散文。甚至,这里有一个优化的编辑器组件来支撑编写富用例定义。这可能是几千个字节。这值得考虑可能的付出。
Given this potential overhead and the errors already made in designing the large cluster Product of Figures 1 and 3 in Part I, the team is now on a mission to reduce the size of every aggregate in the bounded context. Crucial questions arise. Is there a true invariant between BacklogItem and Task that this relationship must maintain? Or is this yet another case where the association can be further broken apart, with two separate aggregates being safely formed? What is the total cost of keeping the design as it is?
潜在的付出和错误已经在大聚类聚合的产品中给出(第一部分Figures 1 and 3),团队现在的任务是在界限上下文中降低每一个聚合的大小。关键问题出现。在BacklogItem和Task之间的关系是否存在必须维护的真实不变性?或者还有没有其他可能进一步打破这种关联关系的例子,使用两个独立的聚合是否是安全的形式?保持它的设计会有哪些开销?
A key to making a proper determination lies in the ubiquitous language. Here is where an invariant is stated: • When progress is made on a backlog item task, the team member will estimate task hours remaining. • When a team member estimates that zero hours are remaining on a specific task, the backlog item checks all tasks for any remaining hours. If no hours remain on any tasks, the backlog item status is automatically changed to done. • When a team member estimates that one or more hours are remaining on a specific task and the backlog item's status is already done, the status is automatically regressed.
作出适当决定的钥匙躺着统一语言中。下面是一些不变性的陈述:
- 当处理一个积压项任务(backlog item task),团队成员将会估计任务剩余时长。
- 当团队成员评估一个特定的任务没有剩余时长时,积压项检查所有的任务是否还存在剩余时间。如果所有任务都没有剩余时间,积压项状态自动变成完成。
- 当团队成员评估发现特定任务存在一些剩余时长,并且积压项的状态已经变成了完成时,状态自动退回。
This sure seems like a true invariant. The backlog item's correct status is automatically adjusted and completely dependent on the total number of hours remaining on all its tasks. If the total number of task hours and the backlog item status are to remain consistent, it seems as if Figure 7 does stipulate the correct aggregate consistency boundary. However, the team should still determine what the current cluster could cost in terms of performance and scalability. That would be weighed against what they might save if the backlog item status could be eventually consistent with the total task hours remaining.
这当然看起来像是真实不变性。积压项(backlog item)的正确状态根据它的所有任务剩余时长自动调整并完成。如果所有任务时长和积压项(backlog item)状态保持一致性,好像图示7做了正确的聚合一致性边界的规定。然而,团队应当继续测定当前的聚类在性能和扩展性方面的代价。这需要与保持积压项(backlog item)状态和总剩余时长最终一致性所能带来的好处做出衡量。
Some will see this as a classic opportunity to use eventual consistency, but we won't jump to that conclusion just yet. Let's analyze a transactional consistency approach, then investigate what could be accomplished using eventual consistency. We can then each draw our own conclusion as to which approach is preferred.
有些人会把这看做是经典/传统的使用最终一致性的时机,但我们不会直接跳到结论。让我们分析一个事务一致性方式,然后研究使用最终一致性可以达到怎样的效果。然后我们可以分别描述结论,哪种方式是完美的。
评估聚合代价(Estimating Aggregate Cost)
As Figure 7 shows, each Task holds a collection of a series of EstimationLogEntry instances. These logs model the specific occasions when a team member enters a new estimation of hours remaining. In practical terms, how many Task elements will each BacklogItem hold, and how many EstimationLogEntry elements will a given Task hold? It's hard to say exactly. It's largely a measure of how complex any one task is and how long a sprint lasts. But some back-of-the-envelope calculations (BOTE) might help [Pearls].
如图示7展示的,每一个任务(Task)持有一个集合的一些列的预估日志实体实例(EstimationLogEntry)。这些日志为当一个团队成员进入一个新的评估剩余时长的特定场合建模。在实践中,每个积压项(BacklogItem)将会持有多少任务(Task),一个给定的任务(Task)又会持有多少预估日志实体元素?这很难精确预估。这是任何一个任务有多复杂和一个冲刺持续多长时间的主要衡量。但是一些不需要复杂计算(BOTE)的任务可能有帮助[Pearls]。
Task hours are usually re-estimated each day after a team member works on a given task. Let's say that most sprints are either two or three weeks in length. There will be longer sprints, but a two-to-three-week timespan is common enough. So let's select a number of days somewhere in between 10 days and 15 days. Without being too precise, 12 days works well since there may actually be more two-week than three-week sprints.
任务时长通常每天在团队成员在任务之上工作后都会重新评估。让我们假设大部分的冲刺都是两到三周的时间。会有更长时间的冲刺,但两到三周的时间跨度足够常见。所以让我们选择一个10~15天之间。没有非常精确,12天很合适因为它可能超过两周两周但小于三周的冲刺。
Next consider the number of hours assigned to each task. Remembering that since tasks must be broken down into manageable units, we generally use a number of hours between 4 and 16. Normally if a task exceeds a 12-hour estimate, Scrum experts suggest breaking it down further. But using 12 hours as a first test makes it easier to simulate work evenly. We can say that tasks are worked on for one hour each of the 12 days of the sprint. Doing so favors more complex tasks. So we'll figure 12 re-estimations per task, assuming that each task starts out with 12 hours allocated to it.
然后考虑为每个任务分配的小时数。记住因为任务必须被拆分到最小的可管理单元,我们通常使用4~16个小时。正常如果一个任务评估超过了12小时,Scrum专家建议进一步的拆分。但是使用12小时作为第一个测试使得更易于平滑的模拟工作。我们可以说在冲刺的12天中每天在任务中工作一个小时。这么做适合更复杂的任务。所以我们将会意识到每个任务有12个重评估,假设每个任务分配了12个小时。
The question remains: How many tasks would be required per backlog item? That too is a difficult question to answer. What if we thought in terms of there being two or three tasks required per layer or hexagonal port-adapter [Cockburn] for a given feature slice? For example, we might count three for user interface layer, two for the application layer, three for the domain layer, and three for the infrastructure layer. That would bring us to 11 total tasks. It might be just right or a bit slim, but we've already erred on the side of numerous task estimations. Let's bump it up to 12 tasks per backlog item to be more liberal. With that we are allowing for 12 tasks, each with 12 estimation logs, or 144 total collected objects per backlog item. While this may be more than the norm, it gives us a chunky BOTE calculation to work with.
问题还在:每个积压项(backlog item)需要多少任务?那同样是一个难以回答的问题。如果我们在这方面认为一个给定特性分解为每一个层或者六边形适配端口[Cockburn]有两到三个任务会怎样?例如,我们也统计到用户接口层三个,应用层两个,领域层三个,和基础设施层三个。这带给我们总共11个任务。这也许是对的或者有点过细,但我们已经在任务预估这边犯错了。让我们更慷慨的提高到每个积压项(backlog item)12个任务。这样我们允许12个任务,每一个有12个评估日志,或者每一个积压项总共144个集合对象。当然也可能远多于正常情况,这给了我们一个”矮胖的”不需要复杂计算(BOTE)的任务。
There is another variable to be considered. If Scrum expert advice to define smaller tasks is commonly followed, it would change things somewhat. Doubling the number of tasks (24) and halving the number of estimation log entries (6) would still produce 144 total objects. However, it would cause more tasks to be loaded (24 rather than 12) during all estimation requests, consuming more memory on each. The team will try various combinations to see if there was any significant impact on their performance tests. But to start they will use 12 tasks of 12 hours each.
还有一个变量需要考虑。如果Scrum专家建议定义一个更小的任务,这会稍微改变一些东西。把任务数量翻倍(24)并把评估日志实体数量减半(6)那么还是产生了总共144个对象。然而,这会造成在所有评估请求时更多的任务被加载(24而不是12),每个都消耗更多的内存。团队将会尝试更多的组合来看看是否会显著改善他们的性能测试。但是开始他们将会使用12个任务每个12小时。
普通使用场景(Common Usage Scenarios)
Now it's important to consider common usage scenarios. How often will one user request need to load all 144 objects into memory at once? Would that ever happen? It seems not, but they need to check. If not, what's the likely high end count of objects? Also, will there typically be multi-client usage that causes concurrency contention on backlog items? Let's see.
现在来考虑通用的使用场景非常重要。会不会频繁的一个请求加载所有的144个对象到内存中?还是这不会发生?看起来不会,但这需要检查。如果不是,那么最大的对象数量可能会是多少?同样的,典型的多客户使用是否会造成积压项(backlog items)的并发竞争?让我们看看。
The following scenarios are based on the use of Hibernate for persistence. Also, each entity type has its own optimistic concurrency version attribute. This is workable because the changing status invariant is managed on the BacklogItem root entity. When the status is automatically altered (to done or back to committed) the root's version is bumped. Thus, changes to tasks can happen independently of each other and without impacting the root each time one is modified, unless it results in a status change. (The following analysis could need to be revisited if using, for example, document-based storage, since the root is effectively modified every time a collected part is modified.)
下面的场景基于使用Hibernate做持久化。同样的,每一个实体类型有它自己的乐观并发版本号属性。这是可行的因为改变状态的不变性是在积压项的根实体管理的。当状态自动修改(转为完成或者提交)根的版本号就会升级。因而,每个修改任务可以单独发生,并且每次已经修改了不会影响根,除非它造成了状态的改变。(下面的分析可能需要重新讨论,如果使用,例如,文档存储,因为根可以在每次修改集合部分是有效修改。)
When a backlog item is first created, there are zero contained tasks. Normally it is not until sprint planning that tasks are defined. During that meeting tasks are identified by the team. As each one is called out, a team member adds it to the corresponding backlog item. There is no need for two team members to contend with each other for the ag- gregate, as if racing to see who can enter new tasks the quickest. That would cause collision and one of the two re- quests would fail (for the same reason adding various parts to Product simultaneously previously failed). However, the two team members would probably soon figure out how counterproductive their redundant work is.
但一个积压项第一次被创建,还不包含任何任务。正常它不会有任务直到冲刺计划定义任务。在会议期间任务被团队识别。像这样一个个被识别出来,一个团队成员把它添加到相应的积压项。这里两个团队成员不需要为此在聚合中相互竞争,好像比赛看谁能更快的占有任务。这会导致冲突,两个请求中的一个将会失败(和之前同时为产品添加各种部分失败的原因相同)。然而,两个团队成员可能会很快指出这些多余的工作是多么的适得其反的。
If the developers learned that multiple users do indeed regularly want to add tasks together, it would change the analysis significantly. That understanding could immediately tip the scales in favor of breaking BacklogItem and Task into two separate aggregates. On the other hand, this could also be a perfect time to tune the Hibernate mapping by setting optimistic-lock option to false. Allowing tasks to grow simultaneously could make sense in this case, especially if they don't pose performance and scalability issues.
如果开发者了解到多个用户确实会想要把任务添加到一起,这将会较大的改变分析。理解这里可能立刻使天平倾斜向拆解积压项和任务为两个单独的聚合。另一边,这可能也是一个调整Hibernate映射设置关闭乐观锁的完美时刻。允许任务同时的增长在这种场景下会有意义,特别是如果他们不想造成性能和扩展性问题。
If tasks are at first estimated at zero hours and later updated to an accurate estimate, we still don't tend to experience concurrency contention, although this would add one additional estimation log entry, pushing our BOTE to 13 total. Simultaneous use here does not change the backlog item status. Again, it only advances to done by going from greater-than zero to zero hours, or regresses to committed if already done and hours are changed from zero to one or more—two uncommon events.
如果任务第一次评估了0小时,然后更新为一个精确的评估,我们仍然不想面临并发竞争,尽管这会添加一个额外的评估日志记录,推动我们的不需要复杂计算(BOTE)日志总共为13个。这里同时使用不会改变积压项的状态。再一次,它仅仅当时间从大于0到为0时前进为完成,或者如果已经变成完成状态但时间从0改为了非0的特殊事件时回退为提交状态。
Will daily estimations cause problems? On day one of the sprint there are usually zero estimation logs on a given task of a backlog item. At the end of day one, each volunteer team member working on a task reduces the estimated hours by one. This adds a new estimation log to each task, but the backlog item's status remains unaffected. There is never contention on a task because just one team member adjusts its hours. It's not until day 12 that we reach the point of status transition. Still, as each of any 11 tasks are reduced to zero hours, the backlog item's status is not altered. It's only the very last estimation, the 144th on the 12th task, that causes automatic status transition to the done state.
每天的评估会造成问题吗?每天一个冲刺积压项的给定任务通常没有评估日志。在第一天的结尾,每一个志愿者团队成员在任务上工作消耗估算一个时长。这为每一个任务添加了一个新的评估日志,但积压项专题仍然不受影响。这还不会在任务上竞争因为仅一个团队成员调整了它的时间。这不会发生直达第12天我们达到了状态转换的点上。仍然一样,11个任务的每一个都减为了0小时,积压项的状态没有发生更改。只是最后一个评估,第12个任务的第144个估算,造成自动的状态转换为完成状态。
This analysis has led the team to an important realization. Even if they alter the usage scenarios, accelerating task completion by double (six days), or even mixing it up completely, it doesn't change anything. It's always the final estimation that transitions the status, which modifies the root. This seems like a safe design, although memory overhead is still in question.
这个分析引导团队回到重要的现实。尽管他们更改了使用场景,加速任务完成(6天),或者甚至完全的混合,这没有改变任何情况。最后一个评估总是转换状态,这将会更改根。这看起来是一个安全的设计,尽管内存过多仍然是一个问题。
内存消耗(Memory Consumption)
Now to address the memory consumption. Important here is that estimations are logged by date as value objects. If a team member re-estimates any number of times on a single day, only the most recent estimation is retained. The latest value of the same date replaces the previous one in the collection. At this point there's no requirement to track task estimation mistakes. There is the assumption that a task will never have more estimation log entries than the number of days the sprint is in progress. That assumption changes if tasks were defined one or more days before the sprint plan- ning meeting, and hours were re-estimated on any of those earlier days. There would be one extra log for each day that occurred.
现在来定位解决内存消耗问题。这里重要的是估算是按日期记录为值对象。如果团队成员在一天内多次重新估算,则仅保留最近的估算。同一日期的最新值替换集合中的前一个值。此时不需要跟踪任务估计错误。假设任务的估计日志条目永远不会超过sprint正在进行的天数。如果在 sprint 计划会议前一天或多天定义了任务,并且在之前的任何一天重新估计了小时数,那么这种假设就会改变。发生的每一天都会有一个额外的日志。
What about the total number of tasks and estimations in memory for each re-estimation? When using lazy loading for the tasks and estimation logs, we would have as many as 12 plus 12 collected objects in memory at one time per request. This is because all 12 tasks would be loaded when accessing that collection. To add the latest estimation log entry to one of those tasks, we'd have to load the collection of estimation log entries. That would be up to another 12 objects. In the end the aggregate design requires one back- log item, 12 tasks, and 12 log entries, or 25 objects maxim- um total. That's not very many; it's a small aggregate. An- other factor is that the higher end of objects (e.g. 25) is not reached until the last day of the sprint. During much of the sprint the aggregate is even smaller.
每次重新估计时,内存中的任务总数和估计数如何?当对任务和估计日志使用延迟加载时,每个请求一次我们将在内存中收集多达12个加12个收集的对象。这是因为访问该集合时将加载所有12个任务。要将最新的估计日志条目添加到其中一项任务中,我们必须加载估计日志条目的集合。那将是另外 12 个对象。最后,聚合设计需要一个积压项目、12 个任务和 12 个日志条目,或者最多总共 25 个对象。那不是很多。这是一个小聚合体。另一个因素是直到 sprint 的最后一天才达到对象的较高端(例如 25)。 在冲刺的大部分时间里,聚合甚至更小。
Will this design cause performance problems because of lazy loads? Possibly, because it actually requires two lazy loads, one for the tasks and one for the estimation log entries for one of the tasks. The team will have to test to investigate the possible overhead of the multiple fetches.
这种设计会因为延迟加载而导致性能问题吗?可能是因为它实际上需要两个延迟加载,一个用于任务,一个用于其中一个任务的估计日志条目。团队将不得不进行测试以调查多次获取的可能开销。
There's another factor. Scrum enables teams to experiment in order to identity the right planning model for their practices. As explained in [Story Points], experienced teams with a well-known velocity can estimate using story points rather than task hours. As they define each task, they can assign just one hour to each task. During the sprint they will re-estimate only once per task, changing one hour to zero when the task is completed. As it pertains to aggregate design, using story points reduces the total number of estimation logs per task to just one, and almost eliminates memory overhead. Later on, ProjectOvation developers will be able to analytically determine (on average) how many actual tasks and estimation log entries exist per back- log item by examining real production data.
还有一个因素。Scrum 使团队能够进行试验,以便为他们的实践确定正确的计划模型。 正如 [故事点] 中所解释的,具有较快速度的经验丰富的团队可以使用故事点而不是任务时间进行估算。当他们定义每项任务时,他们可以只为每项任务分配一小时。在冲刺期间,他们只会对每个任务重新估算一次,当任务完成时将一小时变为零。由于它与聚合设计有关,使用故事点将每个任务的估计日志总数减少到只有一个,并且几乎消除了内存开销。稍后,ProjectOvation 开发人员将能够通过检查实际生产数据分析确定(平均)每个积压项目存在多少实际任务和估计日志条目。
The forgoing analysis was enough to motivate the team to test against their BOTE calculations. After inconclusive results, however, they decide that there were still too many variables to be confident that this design deals well with their concerns. There were enough unknowns to consider an alternative design.
上述分析足以激励团队针对他们的 BOTE 计算进行测试。 然而,在得出不确定的结果后,他们认为仍然存在太多变量,无法确信这种设计能很好地解决他们的担忧。 有足够的未知数来考虑替代设计。
探索另一种替换设计(Exploring Another Alternative Design)
To be thorough, the team wants to think through what they would have to do to make Task an independent aggregate, and if that would actually work to their benefit. What they envision is seen in Figure 8. Doing this would reduce part composition overhead by 12 objects and reduce lazy load overhead. In fact, this design gives them the option to eagerly load estimation log entries in all cases if that would perform best.
为了彻底,团队想要考虑他们必须做些什么才能使任务(Task)成为一个独立的聚合,以及这是否真的对他们有利。他们的设想如图8所示。这样做可以将部件组合开销减少12个对象并减少延迟加载开销。事实上,这种设计让他们可以选择在所有情况下都饥饿模式加载估计日志条目,如果这样做效果最好的话。

The developers agree not to modify separate aggregates, both the Task and the BacklogItem, in the same trans- action. They must determine if they can perform a neces- sary automatic status change within an acceptable time frame. They'd be weakening the invariant's consistency since the status can't be consistent by transaction. Would that be acceptable? They discuss the matter with the do- main experts and learn that some delay between the final zero-hour estimate and the status being set to done, and visa versa, would be acceptable.
开发人员同意不在同一个事务中修改单独的聚合,Task 和 BacklogItem。他们必须确定是否可以在可接受的时间范围内执行必要的自动状态更改。他们会削弱不变量的一致性,因为状态不能通过事务保持一致。这可以接受吗?他们与领域专家讨论此事,并了解到最终零小时估计和设置完成状态之间的一些延迟是可以接受的,反之亦然。
实现最终一致性(Implementing Eventual Consistency)
Here is how it could work. When a Task processes an estimateHoursRemaining() command it publishes a corresponding domain event. It does that already, but the team would now leverage the event to achieve eventual consistency. The event is modeled with the following properties:
这是它的工作原理。当一个任务处理一个estimateHoursRemaining()命令时,它会发布一个相应的领域事件。它已经这样做了,但是团队现在将利用该事件来实现最终的一致性。该事件使用以下属性建模:
1 | public class TaskHoursRemainingEstimated implements DomainEvent { |
A specialized subscriber would now listen for these and delegate to a domain service to coordinate the consistency processing. The service would:
• Use the BacklogItemRepository to retrieve the identified BacklogItem.
• Use the TaskRepository to retrieve all Task instances associated with the identified BacklogItem.
• Execute the BacklogItem command named estimateTaskHoursRemaining() passing the domain event's hoursRemaining and the retrieved Task instances. The BacklogItem may transition its status depending on parameter
一个专门的订阅者现在将监听这些并委托给域服务来协调一致性处理。该服务将:
- 使用BacklogItemRepository检索已识别的BacklogItem。
- 使用TaskRepository来检索所有Task实例关联的BacklogItem。
- 执行名为estimateTaskHoursRemaining()的BacklogItem命令,传递域事件的hoursRemaining和检索到的Task实例。BacklogItem可能会根据参数转换其状态
The team should find a way to optimize this. The three-step design requires all Task instances to be loaded every time a re-estimation occurs. When using our BOTE and advancing continuously toward done, 143 out of 144 times that's unnecessary. This could be optimized this pretty easily. In- stead of using the repository to get all Task instances, they could simply ask it for the sum of all Task hours as calculated by the database:
团队应该找到一种方法来优化这一点。三步设计要求每次重新估计时都加载所有任务实例。当使用我们的BOTE(不需要复杂计算的任务)并不断向这个方向前进时,144次中有143次是不必要的。这可以很容易地进行优化。他们可以简单地询问数据库计算的所有任务小时数的总和,而不是使用存储库来获取所有任务实例:
1 | public class TaskRepositoryImpl implements TaskRepository { |
Eventual consistency complicates the user interface a bit. Unless the status transition can be achieved within a few hundred milliseconds, how would the user interface display the new state? Should they place business logic in the view to determine the current status? That would constitute a smart UI anti-pattern. Perhaps the view would just display he stale status and allow users to deal with the visual in-consistency. That could easily be perceived as a bug, or at least be pretty annoying.
最终的一致性使用户界面有点复杂。除非状态转换可以在几百毫秒内完成,否则用户界面将如何显示新状态?他们是否应该将业务逻辑放在视图中以确定当前状态?这将构成一个“智能UI”的反模式。也许视图只会显示陈旧状态并允许用户处理视觉上的不一致。这很容易被视为一个错误,或者至少很烦人。
The view could use a background Ajax polling request, but that could be quite inefficient. Since the view component could not easily determine exactly when checking for a status update is necessary, most Ajax pings would be unne- cessary. Using our BOTE numbers, 143 of 144 re-estimations would not cause the status update, which is a lot of redundant requests on the web tier. With the right server-side support the clients could instead depend on Comet (a.k.a. Ajax Push). Although a nice challenge, that introduces a completely new technology that the team has no experience using.
视图可以使用后台Ajax轮询请求,但这可能非常低效。由于视图组件无法轻易确定何时需要检查状态更新,因此大多数Ajax ping都是不必要的。使用我们的BOTE(不需要复杂计算的任务)编号,144次重评估中有143次不会导致状态更新,这是Web层上的大量冗余请求。通过正确的服务器端支持,客户端可以改为依赖Comet(也称为 Ajax Push)。虽然是一个不错的挑战,但它引入了一种团队没有使用经验的全新技术。
On the other hand, perhaps the best solution is the simplest. They could opt to place a visual cue on the screen that in- forms the user that the current status is uncertain. The view could suggest a time frame for checking back or refreshing. Alternatively, the changed status will probably show on the next rendered view. That's safe. The team would need to run some user acceptance tests, but it looks hopeful.
另一方面,也许最好的解决方案是最简单的。他们可以选择在屏幕上放置一个视觉提示,告知用户当前状态不确定。该视图可以建议检查或刷新的时间范围。或者,更改后的状态可能会显示在下一个渲染视图上。那是安全的。团队需要进行一些用户验收测试,但看起来很有希望。
这是团队成员的工作吗?(Is It the Team Member’s Job?)
One important question has thus far been completely overlooked. Whose job is it to bring a backlog item's status into consistency with all remaining task hours? Does a team member using Scrum care if the parent backlog item's status transitions to done just as they set the last task's hours to zero? Will they always know they are working with the last task that has remaining hours? Perhaps they will and perhaps it is the responsibility of each team mem- ber to bring each backlog item to official completion.
迄今为止,一个重要的问题被完全忽视了。将积压项目的状态与所有剩余的任务时间保持一致是谁的工作?使用 Scrum 的团队成员是否关心父积压项目的状态转换为完成,就像他们将最后一个任务的小时数设置为零一样?他们会一直知道他们正在处理最后一个有剩余时间的任务吗?也许他们会,也许每个团队成员都有责任将每个积压项目正式完成。
On the other hand, what if there is ever another project stakeholder involved? For example, the product owner or some other person may desire to check the candidate backlog item for satisfactory completion. Maybe they want to use the feature on a continuous integration server first. If they are happy with the developers' claim of completion, they will manually mark the status as done. This certainly changes the game, indicating that neither transactional nor eventual consistency is necessary. Tasks could be split off from their parent backlog item because this new use case allows it. However, if it is really the team members that should cause the automatic transition to done, it would mean that tasks should probably be composed within the backlog item to allow for transactional consistency.
另一方面,如果有另一个项目利益相关者参与其中怎么办?例如,产品所有者或其他人可能希望检查候选积压项目是否令人满意。也许他们想首先在持续集成服务器上使用该功能。如果他们对开发人员的完成声明感到满意,他们将手动将状态标记为完成。这肯定会改变游戏规则,表明事务一致性和最终一致性都不是必需的。任务可以从它们的父积压项目中分离出来,因为这个新的用例允许这样做。但是,如果确实是团队成员应该导致自动转换完成,这意味着任务可能应该在积压项目中组合以允许事务一致性。
Interestingly, there is no clear answer here either, which probably indicates that it should be an optional application preference. Leaving tasks within their backlog item solves the consistency problem, and it's a modeling choice that can support both automatic or manual status transitions.
有趣的是,这里也没有明确的答案,这可能表明它应该是一个可选的应用程序偏好。将任务留在积压项目中解决了一致性问题,这是一种可以支持自动或手动状态转换的建模选择。
This valuable exercise has uncovered a completely new aspect of the domain. It seems like teams should be able to configure a work flow preference. They aren't going to im- plement such a feature now, but they will promote it for further discussion. Asking 'whose job is it?' led them to a few vital perceptions about their domain.
这个有价值的练习揭示了该领域一个全新的方面。似乎团队应该能够配置工作流程首选项。他们现在不打算实现这样的功能,但他们会推广它以供进一步讨论。询问“这是谁的工作?” 引导他们对自己的领域有一些重要的看法。
Next, one of the developers made a very practical suggestion as an alternative to this whole analysis. If they are chiefly concerned with the possible overhead of the story attribute, why not do something about that specifically? They could reduce the total storage capacity for the story and in addition create a new useCaseDefinition property too. They could design it to lazy load, since much of the time it would never be used. Or they could even design it as a separate aggregate, only loading it when needed. With that idea they realized this could be a good time to break the rule to reference external aggregates only by identity. It seems like a suitable modeling choice to use a direct object reference, and declare its object-relational mapping so as to lazily load it. Perhaps that makes sense.
接下来,一位开发人员提出了一个非常实用的建议,作为整个分析的替代方案。如果他们主要关心故事属性的可能开销,为什么不专门做一些事情呢?他们可以减少故事的总存储容量,此外还可以创建一个新的 useCaseDefinition 属性。他们可以将其设计为延迟加载,因为大部分时间它永远不会被使用。或者他们甚至可以将其设计为单独的聚合,仅在需要时加载。有了这个想法,他们意识到这可能是打破仅通过身份引用外部聚合的规则的好时机。使用直接对象引用并声明其对象关系映射以便延迟加载似乎是一种合适的建模选择。也许这是有道理的。
决策时间(Time for Decisions)
Based on all this analysis, currently the team is shying away from splitting Task from BacklogItem. They can't be certain that splitting it now is worth the extra effort, the risk of leaving the true invariant unprotected, or allow- ing users to experience a possible stale status in the view. The current aggregate, as they understand it, is fairly small as is. Even if their common worse case loaded 50 objects rather than 25, it's still a reasonably sized cluster. For now they will plan around the specialized use case definition holder. Doing that is a quick win with lots of benefits. It adds little risk, because it will work now, and in the future if they decide to split Task from BacklogItem.
基于所有这些分析,目前团队正在回避将 Task 从 BacklogItem 中拆分出来。 他们不能确定现在拆分它是否值得付出额外的努力,冒着让真正的不变量不受保护的风险,或者让用户在视图中体验可能的陈旧状态。 据他们了解,目前的总量相当小。 即使他们常见的最坏情况加载了 50 个对象而不是 25 个,它仍然是一个合理大小的集群。 目前,他们将围绕专门的用例定义持有者进行规划。 这样做是一个快速的成功方法,有很多好处。 它增加的风险很小,因为它现在可以工作,将来如果他们决定可以将 Task 从 BacklogItem 中分离出来。
The option to split it in two remains in their hip pocket just in case. After further experimentation with the current design, running it through performance and load tests, as well investigating user acceptance with an eventually con- sistent status, it will become more clear which approach is best. The BOTE numbers could prove to be wrong if in production the aggregate is larger than imagined. If so, the team will no doubt split it into two.
为以防万一,将其一分为二的选项保留在他们的“库袋”中。 在对当前设计进行进一步试验后,通过性能和负载测试运行它,以及调查用户对最终一致状态的接受度之后,哪种方法是最好的将变得更加清晰。 如果生产中的总量比想象的大,那么 BOTE 数字可能被证明是错误的。 如果是这样,该团队无疑会将其一分为二。
If you were a member of the ProjectOvation team, which modeling option would you have chosen?
如果您是 ProjectOvation 团队的成员,您会选择哪个建模选项?
总结(Summary)
Don't shy away from discovery sessions as demonstrated above. That entire effort would require 30 minutes, and per- haps as much as 60 minutes at worse case. It's well worth the time to gain deeper insight into your core domain.
如上所述,不要回避这些发现过程的讨论。 整个工作需要 30 分钟,在更坏的情况下可能需要 60 分钟。 花时间深入了解您的核心领域是非常值得的。
Using a real-world example domain model, we have examined how crucial it is to follow the rules of thumb when designing aggregates:
• Model True Invariants In Consistency Boundaries
• Design Small Aggregates
• Reference Other Aggregates By Identity
• Use Eventual Consistency Outside the Boundary (after asking whose job it is)
If we adhere to the rules, we'll have consistency where necessary, and support optimally performing and highly scalable systems, all while capturing the ubiquitous language of our business domain in a carefully crafted model.
使用现实世界的示例域模型,我们研究了在设计聚合时遵循经验法则的重要性:
- 在一致性边界中为真实不变量建模
- 设计小的聚合
- 通过标识引用其他聚合
- 在标记外使用最终一致性(在询问是谁的工作后)
如果我们遵守规则,我们可以在必要时保持一致性,并打造支持最佳性能和高度可扩展的系统,同时在精心设计的模型中,捕获我们业务领域的统一语言。
Copyright © 2011 Vaughn Vernon. All rights reserved. Effective Aggregate Design is licensed under the Creative Commons Attribution-NoDerivs 3.0 Unported License: http://creativecommons.org/licenses/by-nd/3.0/
致谢(Acknowledgments)
Eric Evans and Paul Rayner did several detailed reviews of this essay. I also received feedback from Udi Dahan, Greg Young, Jimmy Nilsson, Niclas Hedhman, and Rickard Öberg.
引用(References)
[Cockburn] Alistair Cockburn; Hexagonal Architecture; http://alistair.cockburn.us/Hexagonal+architecture
[DDD] Eric Evans; Domain-Driven Design—Tackling Complexity in the Heart of Software.
[Pearls] Jon Bentley; Programming Pearls, Second Edition; http://cs.bell-labs.com/cm/cs/pearls/bote.html
[Story Points] Jeff Sutherland; Story Points: Why are they better than hours?
http://scrum.jeffsutherland.com/2010/04/story-points-why- are-they-better-than.html
个人经历(Biography)
Vaughn Vernon is a veteran consultant, providing architecture, development, mentoring, and training services.
This three-part essay is based on his upcoming book on implementing domain-driven design.
His QCon San Francisco 2010 presentation on context mapping is available on the DDD Community site:
http://dddcommunity.org/library/vernon_2010.
Vaughn blogs here: http://vaughnvernon.co/;
you can reach him by email here: vvernon@shiftmethod.com;
and follow him on Twitter here: @VaughnVernon