
Effective Aggregate Design Part II: Making Aggregates Work Together
DDD有效聚合设计,第二部分:多聚合协作
Part I focused on the design of a number of small aggreg- ates and their internals. In Part II we discuss how aggreg- ates reference other aggregates, as well as how to leverage eventual consistency to keep separate aggregate instances in harmony.
第一部分聚焦设计多个小的聚合和它们的内部交互。在第二部分,我们讨论聚合引用其他聚合,还有如何巧用最终一致性,来持续”和谐”的分离聚合实例。
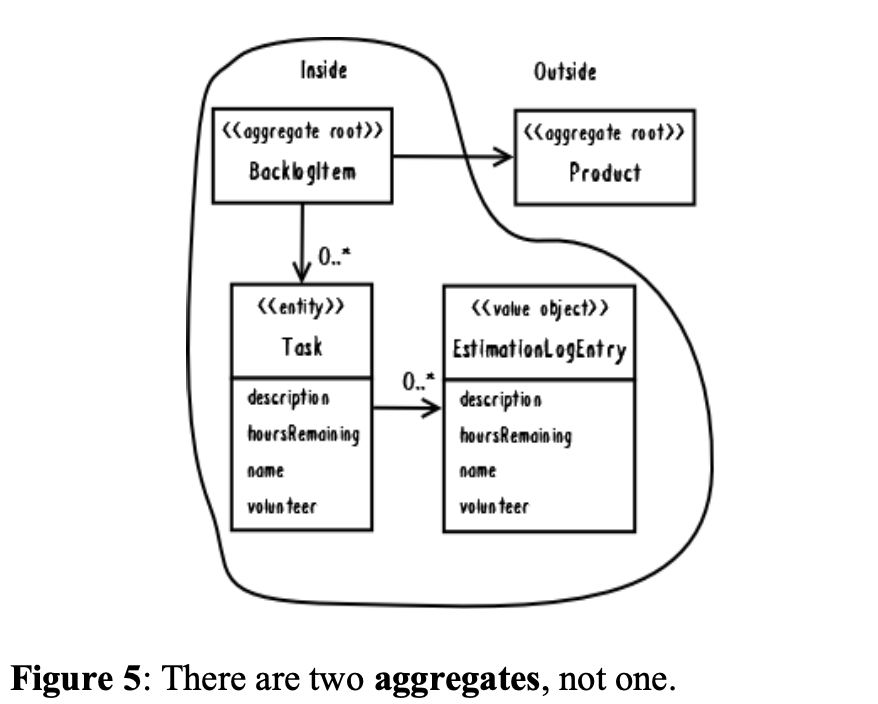
When designing aggregates, we may desire a compositional structure that allows for traversal through deep object graphs, but that is not the motivation of the pattern. [DDD] states that one aggregate may hold references to the root of other aggregates. However, we must keep in mind that this does not place the referenced aggregate inside the consistency boundary of the one referencing it. The reference does not cause the formation of just one, whole aggregate. There are still two (or more), as shown in Figure 5.
当设计聚合时,我们可能希望组合的结构来方便在深度的对象图中遍历,但这不是设计模式的初衷。[DDD]声明一个聚合可能持有到其他聚合根的引用。然而,我们必须牢记这和在一个聚合的致性边界内,引用其他聚合不冲突。引用不会造成所有聚合形成一个。依然会有两个(或多个),入下图例5。
In Java the association would be modeled like this:
Java引用的示例代码如下
1 | public class BacklogItem extends ConcurrencySafeEntity { |
That is, the BacklogItem holds a direct object association to Product.
In combination with what's already been discussed and what's next, this has a few implications:
1.Both the referencing aggregate (BacklogItem) and the referenced aggregate (Product) must not be modified in the same transaction. Only one or the other may be modified in a single transaction.
2.If you are modifying multiple instances in a single transaction, it may be a strong indication that your consistency boundaries are wrong. If so, it is possibly a missed modeling opportunity; a concept of your ubiquitous language has not yet been discovered although it is waving its hands and shouting at you (see Part I).
3.If you are attempting to apply point #2, and doing so influences a large cluster aggregate with all the previously stated caveats, it may be an indication that you need to use eventual consistency (see below) instead of atomic consistency.
这是,积压项(BacklogItem)持有一个直接到产品(Product)的引用。
组合上面我们讨论的内容和将要讨论的,这有几个暗示:
- 无论引用(BacklogItem)和被应用对象(Product)必须不能在同一个事务中修改.
- 如果你再一个事务中修改多个实例,这可能强烈的表明你的一致性边界是错误的。如果是,可能错过了建模的机会;你的统一语言的某个概念还没有被发掘,尽管它可能正在招着手朝你大喊大叫(参考第一部分)。
- 如果你正试图应用第二个观点,但这么做会影响一个有之前阐述的误解的大的聚合,这可能表明你需要使用最终一致性(看下面)而不是原子一致性。
If you don't hold any reference, you can't modify another aggregate. So the temptation to modify multiple aggregates in the same transaction could be squelched by avoiding the situation in the first place. But that is overly limiting since domain models always require some associative connections. What might we do to facilitate necessary associ- ations, protect from transaction misuse or inordinate failure, and allow the model to perform and scale?
如果你不持有任何引用,你不能修改其他聚合。所以试图在同一个事务中修改多个聚合可以首先通过避免这种情况被压制。但是那样可能过于限制,因为域模型总是需要请求一些联合连接。我们可以做什么来使必须的关联更方便,保护它们远离事务滥用,或者过多的失败,并且使模型高性能和可扩展?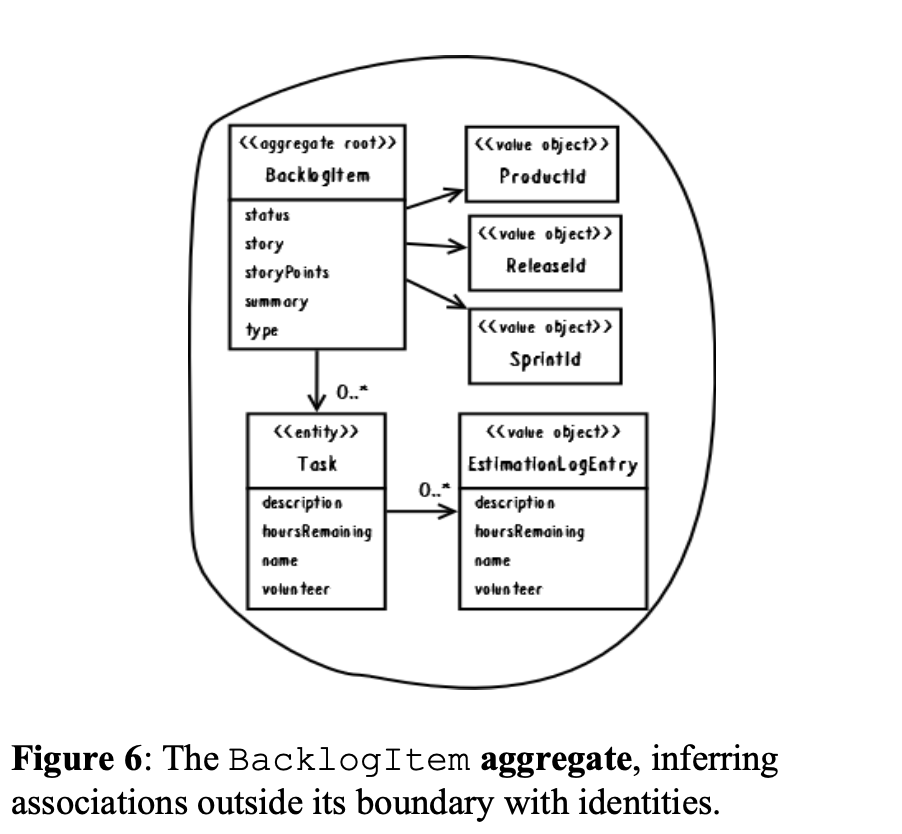
规则:通过标识引用其他聚合(Rule: Reference Other Aggregates By Identity)
Prefer references to external aggregates only by their globally unique identity, not by holding a direct object reference (or “pointer”). This is exemplified in Figure 6. We would refactor the source to:
推荐仅仅通过全局唯一标识引用外部聚合,而不是直接持有对象引用(或者指针)。这在图示6里面已经示范了。我们将会把代码重构为:
1 | public class BacklogItem extends ConcurrencySafeEntity { |
Aggregates with inferred object references are thus automatically smaller because references are never eagerly loaded. The model can perform better because instances require less time to load and take less memory. Using less memory has positive implications both for memory alloca- tion overhead and garbage collection.
拥有推断对象引用的聚合因此自然就变小了,因为引用不会过早加载。模型可以有更好的性能,因为实例加载需要更少的时间和更少的内存。使用更少的内存无论对过分的内存分配和内存回收都有积极的影响。
模型导航(Model Navigation)
Reference by identity doesn't completely prevent navigation through the model. Some will use a repository from inside an aggregate for look up. This technique is called disconnected domain model, and it's actually a form of lazy loading. There's a different recommended approach, however: Use a repository or domain service to look up dependent objects ahead of invoking the aggregate behavior. A client application service may control this, then dispatch to the aggregate:
通过标识引用没有完全拒绝通过模型导航。一些将会使用聚合内部的资源仓库(repository)寻找引用。这些技术被称为分离的域模型,这实时上是延迟加载的一种形式。这里还有另一个不同的途径推荐,不管怎样:在调用一个聚合行为前,使用一个仓库或者域服务来查询依赖对象。一个客户应用服务可能控制这些,然后分发到聚合:
1 | public class ProductBacklogItemService ... { |
Having an application service resolve dependencies frees the aggregate from relying on either a repository or a domain service. Again, referencing multiple aggregates in one request does not give license to cause modification on two or more of them.
有了应用服务解析依赖,把聚合从依赖repository或者领域服务中释放了。另外,在一个请求中引用多个聚合,并没有准许修改两个或者多个聚合。
Limiting a model to using reference only by identity could make it more difficult to serve clients that assemble and render user interface views. You may have to use multiple repositories in a single use case to populate views. If query overhead causes performance issues, it may be worth considering the use of CQRS [Dahan, Fowler, Young]. Or you may need to strike a balance between inferred and direct object reference.
限制模型仅通过标识来引用,会使得客户端更加难以组装和渲染用户界面试图。你可能不得不在一个展示试图的用例中使用多个仓库。如果查询过重造成业务性能问题,使用CQRS[Dahan, Fowler, Young]是值得考虑的。或者你可能需要在推断和只接引用对象之间找到一个平衡。
If all this advice seems to lead to a less convenient model, consider the additional benefits it affords. Making aggreg- ates smaller leads to better performing models, plus we can add scalability and distribution.
如果这些建议看起来会导致不好用的模型,考虑其他的有利于改善的努力。使聚合更小才能创建有利于性能的模型,加上我们可以增加扩展性和分布式。
扩展性和分布式(Scalability and Distribution)
Since aggregates don't use direct references to other aggregates, but reference by identity, their persistent state can be moved around to reach large scale. Almost-infinite scalability is achieved by allowing for continuous repartitioning of aggregate data storage, as explained by Amazon.com's Pat [Helland] in his position paper, Life Beyond Distributed Transactions: an Apostate's Opinion. What we call aggregate he calls entity. But what he describes is still aggregate by any other name; a unit of composition that has transactional consistency. Some NoSql persistence mechanisms support the Amazon-inspired distributed storage. These provide much of what [Helland] refers to as the lower, scale-aware layer. When employing a distributed store, or even when using a SQL database with similar motivations, reference by identity plays an important role.
因为聚合不使用到其他聚合的直接引用,而是通过标识引用,他们的持久状态可以随处移动来达到大并行扩展。通过允许持续的聚合数据重分配可以达到几乎没有限制的扩展能力,像亚马逊的Pat [Helland]在他的主页上解释的,超越分布式事务:变节者的主张。我们叫聚合他称为实体。但是他描述的无论什么名字仍然是聚合;一个拥有事务一致性的组合单元。一些NoSql持久化机制支持亚马逊提出的的分布式存储。它们提供了更多[Helland]引用的底层,可扩展的层。当使用一个分布式存储,或者甚至当使用SQL database达成相同的动机,通过标识引用扮演了重要的角色。
Distribution extends beyond storage. Since there are always multiple bounded contexts at play in a given core domain initiative, reference by identity allows distributed domain models to have associations from afar. When an event-driven approach is in use, message-based domain events containing aggregate identities are sent around the enterprise. Message subscribers in foreign bounded contexts use the identities to carry out operations in their own domain models. Reference by identity forms remote associations or partners. Distributed operations are managed by what [Helland] calls two-party activities; but in publish-subscribe [POSA1, GoF] terms it's multi-party (two or more). Transactions across distributed systems are not atomic. The various systems bring multiple aggregates into a consistent state eventually.
分布式扩展超越存储限制。因为始终会有多个界限上下文加入一个给定的核心域项目,通过标识引用允许分布式域模型远程关联。当使用事件驱动方式,消息为基础的包含聚合标识域事件会在企业内部流转发送。在外部界限上下文的消息订阅者,使用标识来带出行为拥有者的域模型。通过标识引用的形成远程关联或者伙伴。分布式操作通过
[Helland]称为“两党”(two-party)活动管理;但在发布订阅模式[POSA1, GoF]词汇中被称为“多党”(两个或多个)。分布式系统中的事务不是原子的。多样的系统把多个聚合带入了最终一致性状态。
规则:在边界外使用最终一致性(Rule: Use Eventual Consistency Outside the Boundary)
There is a frequently overlooked statement found in the [DDD] aggregate pattern definition. It bears heavily on what we must do to achieve model consistency when multiple aggregates must be affected by a single client request.
"DDD p128: Any rule that spans AGGREGATES will not be expected to be up-to-date at all times. Through event processing, batch processing, or other update mechanisms, other dependencies can be resolved within some specific time."
我们经常忽视[DDD]聚合模式定义中的声明。这对于当一个客户请求影响多个聚合时为达到模型一致性我们必须做的事情是严重缺失的。
DDD p128: 任何贯穿聚合的规则将不会一直保持不变。伴随事件处理,批处理,或者其他更新机制,其他依赖可以在一定时间内解决。
Thus, if executing a command on one aggregate instance requires that additional business rules execute on one or more other aggregates, use eventual consistency. Accepting that all aggregate instances in a large-scale, high-traffic enterprise are never completely consistent helps us accept that eventual consistency also makes sense in the smaller scale where just a few instances are involved.
因此,如果在一个聚合实例上执行一个命令,需要在一个或者多个其他的聚合上执行附加的业务规则,请使用最终一致性。在大扩展,高流量的企业正在接受“所有的聚合实例永远不会完全一致”,这有助于我们接受在那些只涉及几个实例的小扩展的场景,最终一致性同样有意义。
Ask the domain experts if they could tolerate some time delay between the modification of one instance and the others involved. Domain experts are sometimes far more comfortable with the idea of delayed consistency than are developers. They are aware of realistic delays that occur all the time in their business, whereas developers are usually indoctrinated with an atomic change mentality. Domain experts often remember the days prior to computer automation of their business operations, when various kinds of delays occurred all the time and consistency was never immediate. Thus, domain experts are often willing to allow for reasonable delays—a generous number of seconds, minutes, hours, or even days—before consistency occurs.
咨询领域专家他们是否可以容忍在修改一个实例和其他涉及的实例时的一些时间延迟。领域专家有时比开发人员更加坦然的接受一致性延迟。他们知道现实的延迟几乎在他们所有的业务都会出现,而开发人员通常被灌输原子修改的理念。领域专家通常提起 优选于他们的业务操作的电脑自动化的日期,当很多类型的延迟一直发生,并且一致性一直不是立即一致。
There is a practical way to support eventual consistency in a DDD model. An aggregate command method publishes a domain event that is in time delivered to one or more asynchronous subscribers:
有一种实践方式来支持DDD模型的最终一致性。一个聚合命令方法发布一个域事件传递到一个或者多个异步订阅者:
1 | public class BacklogItem extends ConcurrencySafeEntity { |
These subscribers each then retrieve a different yet corresponding aggregate instance and execute their behavior based on it. Each of the subscribers executes in a separate transaction, obeying the rule of aggregate to modify just one instance per transaction.
订阅者收到消息后取出一个相应的不同的聚合实例并执行他们的行为。每一个订阅者在一个单独的事务中执行,服从一个聚合在每个事务中仅修改一个实例的规则。
What happens if the subscriber experiences concurrency contention with another client, causing its modification to fail? The modification can be retried if the subscriber does not acknowledge success to the messaging mechanism. The message will be redelivered, a new transaction started, a new attempt made to execute the necessary command, and a corresponding commit. This retry process can continue until consistency is achieved, or until a retry limit is reached. If complete failure occurs it may be necessary to compensate, or at a minimum to report the failure for pending intervention.
如果订阅者发生并发争抢会出现什么情况,导致修改失败?如果订阅者不能告知消息系统处理成功,修改消息可以重试。消息将会重新投递,一个新的事务将会开启,一个新的重试来执行必须的命令,以及对应的提交。这种重试进程会一直持续知道到达一致性,或者直到达到重试限制。如果最终失败发生可能需要补偿,或者至少报告失败等待介入。
What is accomplished by publishing the BacklogItem- Committed event in this specific example? Recalling that BacklogItem already holds the identity of the Sprint it is committed to, we are in no way interested in maintain- ing a meaningless bidirectional association. Rather, the event allows for the eventual creation of a Committed-BacklogItem so the Sprint can make a record of work commitment. Since each CommittedBacklogItem has an ordering attribute, it allows the Sprint to give each BacklogItem an ordering different than Product and Release have, and that is not tied to the BacklogItem instance's own recorded estimation of Business- Priority. Thus, Product and Release each hold similar associations, namely ProductBacklogItem and ScheduledBacklogItem, respectively.
在这个例子中通过发布积压项(BacklogItem)提交事件到底完成了什么呐?回忆一下积压项(BacklogItem)已经持有了他们要提交的冲刺(Sprint)的标识,我们完全不需要维护一个没有意义的双向引用。宁愿事件允许最终创建一个提交的积压项(BacklogItem),这样冲刺(Sprint)可以创建一个工作提交。因为每一个提交的积压项(BacklogItem)拥有一个有序的属性,它允许冲刺(Sprint)为每一个积压项(BacklogItem)分配一个不同于产品(Product)和版本(Release)拥有的顺序,并且这不会绑定到积压项(BacklogItem)实例自己拥有的记录的业务优先级。因而,产品(Product)和版本(Release)每一个持有相似的关联,命名为产品积压项(ProductBacklogItem)和已规划(ScheduledBacklogItem)。
This example demonstrates how to use eventual consistency in a single bounded context, but the same technique can also be applied in a distributed fashion as previously described.
这个例子演示了如何在单个界限上下文中使用最终一致性,但同样的技术也可以应用到前面描述的分布式场景。
明确职责(Ask Whose Job It Is)
Some domain scenarios can make it very challenging to de- termine whether transactional or eventual consistency should be used. Those who use DDD in a classic/traditional way may lean toward transactional consistency. Those who use CQRS may tend to lean toward eventual consistency. But which is correct? Frankly, neither of those leanings provide a domain-specific answer, only a technical prefer- ence. Is there a better way to break the tie?
一些领域场景可能很难决定应该使用事务还是最终一致性。那些使用经典/传统方式DDD的人可能倾向于事务一致性。那些使用CQRS的人可能倾向于使用最终一致性。但是那种是正确的呐?坦白的说,没有任何倾向提供了一种领域规范的答案,只有一种技术完美。那么是否有一个更好的方式打破约束?
Discussing this with Eric Evans revealed a very simple and sound guideline. When examining the use case (or story), ask whether it's the job of the user executing the use case to make the data consistent. If it is, try to make it transactionally consistent, but only by adhering to the other rules of aggregate. If it is another user's job, or the job of the system, allow it to be eventually consistent. That bit of wisdom not only provides a convenient tie breaker, it helps us gain a deeper understanding of our domain. It exposes the real system invariants: the ones that must be kept transactionally consistent. That understanding is much more valu- able than defaulting to a technical leaning.
在和Eric Evans讨论中发现一个更简单、可靠的准则。当检查用例(故事)时,试着问一下,用户执行用例保持数据一致是否是它的任务。如果是,试着使它事务一致,但请仅通过依附于其他的聚合规则。如果有其他的用户任务,或者系统任务(单独修改),允许它改为最终一致性。这是比较明智的,它不仅仅是提供了一个种方便的打破约束的方式,还帮助我们更深入的理解了我们的域。这暴露了一个真实的系统约束:那些必须保持事务一致性的聚合。这个理解比技术倾向更有价值。
This is a great tip to add to aggregate rules of thumb. Since there are other forces to consider, it may not always lead to the final answer between transactional and eventual consistency, but will usually provide deeper insight into the model. This guideline is used later in Part III when the team revisits their aggregate boundaries.
这是一个伟大而首要的需要添加到聚合规则的建议。因为这里有其他必须要考虑的,它可能不能总是在事务和最终一致间导向最终答案,但通常会提供更深的模型理解。这个指导准则会在后面的第三部分,当团队重新讨论他们的聚合界限时使用。
为何打破规则(Reasons To Break the Rules)
An experienced DDD practitioner may at times decide to persist changes to multiple aggregate instances in a single transaction, but only with good reason. What might some reasons be? I discuss four reasons here. You may experience these and others.
一个有经验的DDD实践者可能有时决定在一个事务中持久化多个聚合实例的变动,除非有更好的原因。那么更好的原因是什么?我这里讨论了四个原因。你可能对其中的一些有经历。
原因一:用户界面便捷 (Reason One: User Interface Convenience)
Sometimes user interfaces, as a convenience, allow users to define the common characteristics of many things at once in order to create batches of them. Perhaps it happens frequently that team members want to create several backlog items as a batch. The user interface allows them to fill out all the common properties in one section, and then one-by-one the few distinguishing properties of each, eliminating repeated gestures. All of the new backlog items are then planned (created) at once:
有时用户界面,为了方便,允许用户一次为很多事情定义通用特性来达到批量创建。团队成员想要一批创建多个积压项(backlog items),这可能经常发生。用户界面允许他们在一个区域填写所有的相同属性,然后一个个的为它们填写有区别的属性,来剔除重复的操作。然后所有的新积压项(backlog items)就被一次创建了:
1 | public class ProductBacklogItemService ... { |
Does this cause a problem with managing invariants? In this case, no, since it would not matter whether these were created one at a time or in batch. The objects being instantiated are full aggregates, which themselves maintain their own invariants. Thus, if creating a batch of aggregate instances all at once is semantically no different than creating one at a time repeatedly, it represents one reason to break the rule of thumb with impunity.
这样管理不变性会造成问题吗?在这个例子中,不会,因为这些实例是否同时或一批创建完全没有关系。这些正被实例化的对象全部是聚合,他们每一个都管理自己的不变性。因此,如果一次同时创建一批聚合实例,和重复的每次创建一个没有区别,它描绘了首要的无损打破规则的一个原因。
Udi Dahan recommends avoiding the creation of special batch application services like the one above. Instead, a [Message Bus] would be used to batch multiple application service invocations together. This is done by defining a logical message type to represent a single invocation, with the client sending multiple logical messages together in the same physical message. On the server-side the [Message Bus] processes the physical message in a single transaction, delivering each logical message individually to a class which handles the “plan product backlog item message” for processing (equivalent in implementation to an application service method), all either succeeding or failing together.
Udi Dahan建议避免创建特殊的类似上面的批量应用服务。作为替代,消息总线[Message Bus]将会被用来做批量多应用服务的合并调用。这通过定义一个代表一次调用的逻辑消息类型来实现,伴随客户端同一个物理消息会发送多个逻辑消息。在服务端消息总线在一个事务中处理物理消息,单独的传递每一个逻辑消息到一个类来处理,操做“计划一个产品积压项消息”(等同于在应用服务方法中实现),所有这样要么一起成功要么一起是吧。
原因二:缺少技术机制(Reason Two: Lack of Technical Mechanisms)
Eventual consistency requires the use of some kind of out-of-band processing capability, such as messaging, timers, or background threads. What if the project you are working on has no provision for any such mechanism? While most of us would consider that strange, I have faced that very limitation. With no messaging mechanism, no background timers, and no other home-grown threading capabilities, what could be done?
最终一致性要求使用一些类型的带外(out-of-band)处理能力,例如消息,定时器,或者后台线程。如果你正在开发的工程没有预备任何这些机制将会如何?可能我们大部分人将会考虑奇怪的方案,我曾经面临过这样的限制。没有消息机制,没有后台定时器,还没有其他的自产的线程能力,那么可以做什么呐?
If we aren't careful, this situation could lead us back toward designing large cluster aggregates. While that might make us feel like we are adhering to the single transaction rule, as previously discussed it would also degrade performance and limit guardedscalability. To avoid that, perhaps we could instead change the system's aggregates altogether, forcing the model to solve our challenges. We've already considered the possibility that project specifications may be jealously , leaving us little room for negotiating previously unimagined domain concepts. That's not really the DDD way, but sometimes it does happen. The conditions may allow for no reasonable way to alter the modeling circumstances in our favor. In such cases project dynamics may force us to modify two or more aggregate in- stances in one transaction. However obvious this might seem, such a decision should not be made too hastily.
如果我们不够小心谨慎,这种情况可能导致我们回到设计大聚类聚合。虽然这可能使我们感觉像在遵循单事务规则,如上面讨论的它也会降低性能和限制扩展。为避免这些,可能作为替换,我们会修改系统的全部聚合,强制模型解决我们面临的挑战。我们已经考虑了警惕工程规范的可能性,为我们谈判之前未设想的域概念争取了空间。但这不是真正的DDD的路径,虽然有时这可能发生。条件可能允许没有原因的方式以我们的喜好修改建模细节。在这种动态的项目情况,有时可能强制我们在一个事务中修改两个或更多聚合实例
。然而显然的似乎不应该做这种匆忙的决定。
Consider an additional factor that could further support diverting from the rule: user-aggregate affinity. Are the busi- ness work flows such that only one user would be focused on one set of aggregate instances at any given time? Ensuring user-aggregate affinity makes the decision to alter multiple aggregate instances in a single transaction more sound since it tends to prevent the violation of invariants and transactional collisions. Even with user-aggregate affinity, in rare situations users may face concurrency conflicts. Yet each aggregate would still be protected from that by using optimistic concurrency. Anyway, concurrency conflicts can happen in any system, and even more fre- quently when user-aggregate affinity is not our ally. Besides, recovering from concurrency conflicts is straightforward when encountered at rare times. Thus, when our design is forced to, sometimes it works out well to modify multiple aggregate instances in one transaction.
考虑规则里一个有趣的额外因素可以更好的支持:用户聚合联姻。业务流程是否导致,在任何时间仅一个用户会聚焦在一个集合的聚合实例?为确保用户聚合联姻,决定将多个聚合实例改为在一个事务中的声音会更多,因为它趋向于阻止不变性和事务冲突。即使用户聚合联姻,在一些情况用户可能会面临并发冲突。但是每一个聚合将仍然可以通过使用乐观并发保护避免这些。总之,并发冲突可能在任何系统发生,并且当用户聚合联姻不作为我们同盟时将更频繁。另外,遇到的少数情况下,从并发冲突中恢复是易懂的。因而,当我们的设计不得不(使用用户聚合联姻),有时它在一个事务中修改多个聚合实例时工作的很好。
原因三:全局事务(Reason Three: Global Transactions)
Another influence considered is the effects of legacy technologies and enterprise policies. One such might be the need to strictly adhere to the use of global, two-phase commit transactions. This is one of those situations that may be impossible to push back on, at least in the short term.
另一个被考虑的影响是前人留下的技术和企业政策的影响。其中一个可能是需要严格遵循使用全局的、两阶段提交的事务。这是其中的一种可能短期内不能回退的情况。
Even if you must use a global transaction, you don't necessarily have to modify multiple aggregate instances at once in your local bounded context. If you can avoid doing so, at least you can prevent transactional contention in your core domain and actually obey the rules of aggregates as far as it depends on you. The downside to global transactions is that your system will probably never scale as it could if you were able to avoid two-phase commits and the immediate consistency that goes along with them.
尽管你必须使用全局事务,你不必在你的本地界限上下文一次修改多个聚合实例。如果你可以避免这样做,至少你可以在你的核心域避免事务争夺,并且事实上让依赖于你的聚合遵循聚合的规则。全局事务的负面因素是你的系统将大概不能随意扩展,如果你有能力避免伴随他们的两阶段提交和直接持久化。
原因四:查询性能(Reason Four: Query Performance)
There may be times when it's best to hold direct object references to other aggregates. This could be used to ease repository query performance issues. These must be weighed carefully in the light of potential size and overall performance trade-off implications. One example of breaking the rule of reference by identity is given in Part III.
有时当直接持有到其他聚合的对象的引用是最好的。这可以用来缓和仓库的查询性能问题。这必须小心的按照潜在的数量和全局的性能衡量。在第三部分会给出一个打破通过标识引用规则的例子。
遵守规则(Adhering to the Rules)
You may experience user interface design decisions, technical limitations or stiff policies in your enterprise environ- ment, or other factors, that require you to make some compromises. Certainly we don't go in search of excuses to break the aggregate rules of thumb. In the long run, adhering to the rules will benefit our projects. We'll have consistency where necessary, and support optimally performing and highly scalable systems.
你可能经历过用户界面设计决定,技术限制或者你的企业的僵硬政策环境,或者其他因素,需要你做一些折中。当然我们不会找接口来打破首要聚合规则。长期来看,遵守规则将会有利于我们的项目。我们将会拥有需要的一致性,和支持最佳的性能和高扩展的系统。
第三部分预告(Looking Forward to Part III)
We are now resolved to design small aggregates that form boundaries around true business invariants, to prefer reference by identity between aggregates, and to use eventual consistency to manage cross-aggregate dependencies. How will adhering to these rules affect the design of our Scrum model? That's the focus of Part III. We'll see how the project team rethinks their design again, applying their new-found techniques.
我们现在已经解决了在组成真实业务不变性边界内的小聚合设计,提出了通过标识在聚合间引用,以及使用最终一致性来管理跨聚合依赖。如何综合这些规则来设计我们的的Scrum模型呐?这是第三部分的核心聚集点。我们将会看到项目团队如何重新思考他们的设计,和如何应用他们新发现的技巧。
致谢(Acknowledgments)
Eric Evans and Paul Rayner did several detailed reviews of this essay. I also received feedback from Udi Dahan, Greg Young, Jimmy Nilsson, Niclas Hedhman, and Rickard Öberg.
引用(References)
[DDD] Eric Evans; Domain-Driven Design—Tackling Complexity in the Heart of Software.
[Dahan] Udi Dahan; Clarified CQRS; http://www.udidahan.com/2009/12/09/clarified-cqrs/
[Fowler] Martin Fowler; CQRS; http://martinfowler.com/bliki/CQRS.html
[GoF] Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides; Design Patterns: Elements of Reusable Object-Oriented Software; see the Observer pattern.
[Helland] Pat Helland; Life beyond Distributed Transactions: an Apostate’s Opinion; http://www.ics.uci.edu/~cs223/papers/cidr07p15.pdf
[Message Bus] NServiceBus is a framework that supports this pattern; http://www.nservicebus.com/
[POSA1] Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad; Pattern-Oriented Software Architecture Volume 1: A System of Patterns; see the Publisher-Subscriber pattern.
[Young] Greg Young; CQRS and Event Sourcing; http://codebetter.com/gregyoung/2010/02/13/cqrs-and- event-sourcing/
个人经历(Biography)
Vaughn Vernon is a veteran consultant, providing architecture, development, mentoring, and training services.
This three-part essay is based on his upcoming book on implementing domain-driven design.
His QCon San Francisco 2010 presentation on context mapping is available on the DDD Community site:
http://dddcommunity.org/library/vernon_2010.
Vaughn blogs here: http://vaughnvernon.co/;
you can reach him by email here: vvernon@shiftmethod.com;
and follow him on Twitter here: @VaughnVernon