
Effective Aggregate Design Part I: Modeling a Single Aggregate
有效聚合设计,第一部分:单聚合建模
Clustering entities and value objects into an aggregate with a carefully crafted consistency boundary may at first seem like quick work, but among all [DDD] tactical guidance, this pattern is one of the least well understood.
用精心设计的一致性边界将实体和值对象聚集到一个聚合中,乍一看似乎很快,但在所有 [DDD] 战术指导中,这种模式是最不被理解的模式之一。
To start off, it might help to consider some common questions. Is an aggregate just a way to cluster a graph of closely related objects under a common parent? If so, is there some practical limit to the number of objects that should be allowed to reside in the graph? Since one aggregate instance can reference other aggregate instances, can the associations be navigated deeply, modifying various objects along the way? And what is this concept of invariants and a consistency boundary all about? It is the answer to this last question that greatly influences the answers to the others.
首先,它对于考虑一些常见问题可能会有所帮助。 聚合只是一种将密切相关的对象图聚集在一个共同的父对象下的方法吗? 如果是这样,对于应该允许驻留在图中的对象数量是否有一些实际限制? 由于一个聚合实例可以引用其他聚合实例,是否可以深入导航关联,沿途修改各种对象? 这个不变量和一致性边界的概念是什么? 正是这最后一个问题的答案极大地影响了其他问题的答案。
There are various ways to model aggregates incorrectly. We could fall into the trap of designing for compositional convenience and make them too large. At the other end of the spectrum we could strip all aggregates bare, and as a result fail to protect true invariants. As we'll see, it's imperative that we avoid both extremes and instead pay attention to the business rules.
通常有很多错误聚合建模的方式。 我们可能掉入组合设计便利性的陷阱,并把它们设计的非常大。另一种极端,我们可以剥离所有聚合,结果导致无法保护真正的不变量。正如我们将看到的,我们必须避免两个极端,而是关注业务规则,这至关重要。
设计一个敏捷开发管理应用(Designing a Scrum Management Application)
The best way to explain aggregates is with an example. Our fictitious company is developing an application to support Scrum-based projects, ProjectOvation. It follows the traditional Scrum project management model, complete with product, product owner, team, backlog items, planned releases, and sprints. If you think of Scrum at its richest, that's where ProjectOvation is headed. This provides a familiar domain to most of us. The Scrum terminology forms the starting point of the ubiquitous language. It is a subscription-based application hosted using the software as a service (SaaS) model. Each subscribing organization is registered as a tenant, another term for our ubiquitous language.
解释聚合的最好方法是举个例子。 我们虚构的公司正在开发一个应用程序来支持基于 Scrum 的项目,ProjectOvation。 它遵循传统的 Scrum 项目管理模型,包括产品、产品负责人、团队、待办事项、计划发布和冲刺。 你想象的最完美的Scrum,那就是 ProjectOvation 的发展方向。 这为我们大多数人提供了一个熟悉的领域。 Scrum 术语构成了无处不在的语言的起点。 它是一个使用软件即服务 (SaaS) 模型托管的基于订阅的应用程序。 每个订阅组织都注册为租户,这是我们无处不在的语言的另一个术语。
The company has assembled a group of talented Scrum experts and Java developers. However, their experience with DDD is somewhat limited. That means the team is going to make some mistakes with DDD as they climb a difficult learning curve. They will grow, and so can we. Their struggles may help us recognize and change similar unfavorable situations we've created in our own software.
公司组织了一些租户的Scrum的专家和Java开发人员。然后,他们的DDD的经验却又一些局限。这就是说团队可能会在实践DDD困难的学习曲线时犯一些错误。他们将会成长,那么学完之后我们也会成长。他们实践中的挣扎,可能会帮助我们识别和改正,我们创建的软件中的相同的不幸场景。
The concepts of this domain, along with its performance and scalability requirements, are more complex than any of them have previously faced. To address these issues, one of the DDD tactical tools that they will employ is aggregate.
这个领域中的概念,伴随它的性能和扩展需求,比他们之前遇到的任何项目更加复杂。为了定位这些问题,他们要使用的一个DDD的战术工具就是聚合。
How should the team choose the best object clusters? The aggregate pattern discusses composition and alludes to information hiding, which they understand how to achieve. It also discusses consistency boundaries and transactions, but they haven't been overly concerned with that. Their chosen persistence mechanism will help manage atomic commits of their data. However, that was a crucial misunderstanding of the pattern's guidance that caused them to regress. Here's what happened. The team considered the following statements in the ubiquitous language:
• Products have backlog items, releases, and sprints.
• New product backlog items are planned.
• New product releases are scheduled.
• New product sprints are scheduled.
• A planned backlog item may be scheduled for release.
• A scheduled backlog item may be committed to a sprint.
From these they envisioned a model, and made their first attempt at a design. Let's see how it went.
团队应该如何选择最好的对象群集?聚合模式讨论组合和暗指信息隐藏,以及哪些他们理解如何实现。它也讨论一致性边界和事务,但他们没有过于担心那些。他们选择的持久化机器会帮助管理他们的数据的原子提交。然而,这是模式指导的一个严重的造成退步的误区。这是经常发生的事情。团队考虑了如下统一语言中的表述:
- 产品包含需求积压,版本和冲刺。
- 新的需求积压项创建。
- 新的产品版本规划。
- 新的冲刺计划。
- 一个计划的需求积压项可能被规划到了版本。
- 一个计划的需求积压项可能被提交到一个冲刺。
基于上述他们预想了一个模型,并做了他们的首次设计尝试。让我们看看它的进展如何。
初次尝试:大集群聚合(First Attempt: Large-Cluster Aggregate)
The team put a lot of weight on the words “Products have” in the first statement. It sounded to some like composition, that objects needed to be interconnected like an object graph. Maintaining these object life cycles together was considered very important. So, the developers added the following consistency rules into the specification:
• If a backlog item is committed to a sprint, we must not allow it to be removed from the system.
• If a sprint has committed backlog items, we must not allow it to be removed from the system.
• If a release has scheduled backlog items, we must not allow it to be removed from the system.
• If a backlog item is scheduled for release, we must not allow it to be removed from the system.
在首次陈述中,团队把大部分重点放在了”产品包含什么“。这听起来想组合,对象需要像一个对象图一样内部相互联系。通常认为维护这些对象的生命周期非常重要。所以,开发人员在规范中添加了下面的一致性规则:
- 如果一个需求积压项(backlog item)被提交到冲刺(sprint),我们必须不允许需求积压项(backlog item)被删除。
- 如果一个冲刺(sprint)已经提交需求积压项(backlog item),我们必须不允许需求积压项冲刺(sprint)被删除。
- 如果一个版本(release)已经规划了需求积压项(backlog item),我们必须不允许版本(release)被删除。
- 如果一个需求积压项(backlog item)被规划到一个版本(release),我们必须不允许需求积压项(backlog item)被删除。
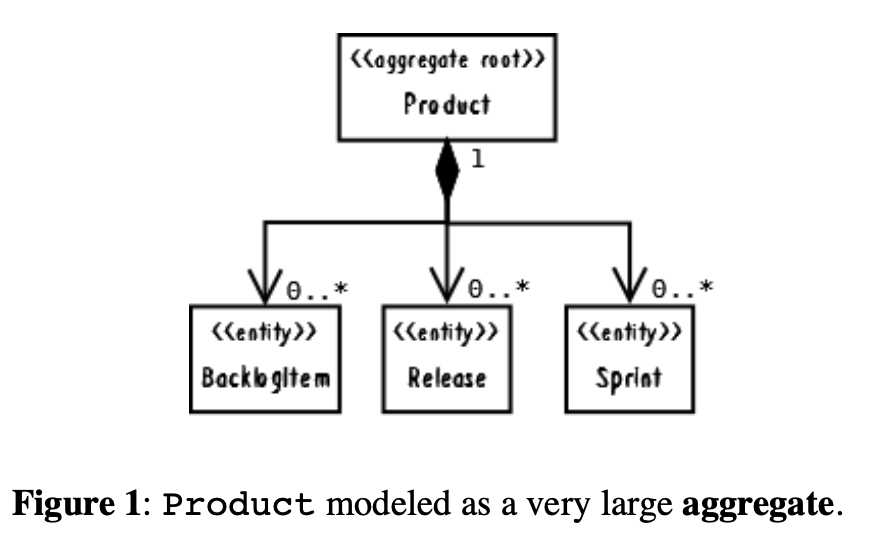
As a result, Product was first modeled as a very large aggregate. The root object, Product, held all Backlog Item, all Release, and all Sprint instances associated with it. The interface design protected all parts from inadvertent client removal. This design is shown in the follow- ing code, and as a UML diagram in Figure 1:
结果,产品开始被建模成了一个非常大的聚合。根对象,产品,持有所有和它有关的需求积压项(backlog item),所有的版本(release),所有的冲刺(sprint)实例。
接口设计为保护所有部分不被客户端不经意删除。这个设计的可用用下面的代码表示,UML图为Figure 1:
1 | public class Product extends ConcurrencySafeEntity { |
The big aggregate looked attractive, but it wasn't truly practical. Once the application was running in its intended multi-user environment it began to regularly experience transactional failures. Let's look more closely at a few client usage patterns and how they interact with our technical solution model. Our aggregate instances employ optimistic concurrency to protect persistent objects from simultaneous overlapping modifications by different clients, thus avoiding the use of database locks. Objects carry a version number that is incremented when changes are made and checked before they are saved to the database. If the version on the persisted object is greater than the version on the client's copy, the client's is considered stale and updates are rejected.
大的聚合对象看起来很诱人,但它不是可行的实践。一旦程序运行在它预设的多用户环境,就会开始经常遇到事务失败。让我们进一步看几个客户使用模式,看他们如何和我们的技术方案模型交互。我们的聚合实例采用乐观并发锁来保护持久对象不被不同用户同时覆盖修改,因此避免使用数据库锁。对象承载了一个每次修改就递增的版本号,并且每次保存数据库前都会校验版本号。如果持久对象版本号大于客户端持有副本,客户端被认为是陈旧的,更新会被拒绝。
Consider a common simultaneous, multi-client usage scenario:
• Two users, Bill and Joe, view the same Product marked as version 1, and begin to work on it.
• Bill plans a new BacklogItem and commits. The Product version is incremented to 2.
• Joe schedules a new Release and tries to save, but his commit fails because it was based on Product version 1.
考虑一个常见的同时,多用户使用场景:
- 两个用户,Bill和Joe,浏览同一个版本1的产品(Product),并开始在这个版本上开始工作。
- Bill规划了一个新积压项(BacklogItem)和提交。产品(Product)版本号被增加到了2.
- Joe规划了一个新的版本(Release)并且试图保存,但是他的提交失败了,因为它是基于产品(Product)的版本1.
Persistence mechanisms are used in this general way to deal with concurrency. If you argue that the default concurrency configurations can be changed, reserve your verdict for a while longer. This approach is actually important to protecting aggregate invariants from concurrent changes.
通常使用持久性机制来处理并发。如果有说默认的并发配置可以修改有争议,先保留一会你的最终决议。这种途径事实上对于保护并发修改下的聚合不变性是非常重要的。
These consistency problems came up with just two users. Add more users, and this becomes a really big problem. With Scrum, multiple users often make these kinds of overlapping modifications during the sprint planning meeting and in sprint execution. Failing all but one of their requests on an ongoing basis is completely unacceptable.
这些并发问题在仅仅两个用户的情况下就会出现。添加更多的用户,那么这就变成了一个真正的大问题。使用Scrum,多个用户在冲击计划会议和执行中经常做这种类型的覆盖性修改。在一个不断变化的基础上大部分都失败而仅仅有一个请求完成是不可接受的。
Nothing about planning a new backlog item should logically interfere with scheduling a new release! Why did Joe's commit fail? At the heart of the issue, the large cluster aggregate was designed with false invariants in mind, not real business rules. These false invariants are artificial constraints imposed by developers. There are other ways for the team to prevent inappropriate removal without being arbitrarily restrictive. Besides causing transactional issues, the design also has performance and scalability drawbacks.
计划一个新的积压项(backlog item)与规划一个新版本没有任何相抵触!为什么Joe提交失败了?这个问题的核心,大聚合对象在思想中被设计了错误的一致性,而不是真正的业务规则。这些错误的一致性是开发者假设的人为的约束。团队有其他的方式避免不适当的删除而不必任意的约束。除造成事务问题之外,这样的设计同时有性能和扩展性的弊端。
二次尝试:多聚合(Second Attempt: Multiple Aggregates)
Now consider an alternative model as shown in Figure 2, in which we have four distinct aggregates. Each of the dependencies is associated by inference using a common ProductId, which is the identity of Product considered the parent of the other three.
那么现在考虑一个下图2展示的替代模型,如图我们有四个独立的聚合。每一个独立依赖是一个对通用的ProductId的引用,它是产品(Product)的唯一标识被认为是tree的其他节点的父节点。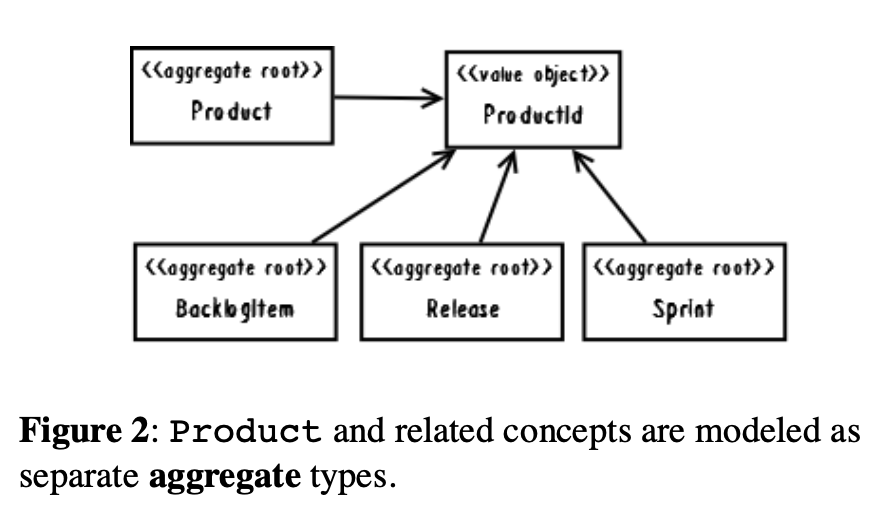
Breaking the large aggregate into four will change some method contracts on Product. With the large cluster aggregate design the method signatures looked like this:
把大聚合拆解为四个将会改变Product聚合的方法合约。大聚合对象时设计的方法签名就像下面代码所示:
1 | public class Product ... { |
All of these methods are [CQS] commands. That is, they modify the state of the Product by adding the new ele- ment to a collection, so they have a void return type. But with the multiple aggregate design, we have:
所有这些方法是[CQS]命令。这就是说,它们修改通过为集合添加新的元素来修改产品状态,所以它们都是返回void类型。但如果使用多聚合设计,代码将会变成:
1 | public class Product ... { |
These redesigned methods have a [CQS] query contract, and act as factories. That is, they each respectively create a new aggregate instance and return a reference to it. Now when a client wants to plan a backlog item, the transactional application service must do the following:
这些重新设计的方法有一个[CQS]的查询合约,并充当工程方法。这就是说,它们每个都负责创建一个新的聚合实例并返回一个对实例的引用。现在当一个客户想要计划一个需求积压项,事务性的应用服务必须按照如下做:
1 | public class ProductBacklogItemService ... { |
So we've solved the transaction failure issue by modeling it away. Any number of BacklogItem, Release, and Sprint instances can now be safely created by simultaneous user requests. That's pretty simple.
所以,我们就通过重新建模解决了事务失败的问题。任意数量的BacklogItem, Release和Sprint实例,现在都可以被并发的用户请求安全的创建。这非常的简洁。
However, even with clear transactional advantages, the four smaller aggregates are less convenient from the perspective of client consumption. Perhaps instead we could tune the large aggregate to eliminate the concurrency issues. By setting our Hibernate mapping optimistic-lock option to false, the transaction failure domino effect goes away. There is no invariant on the total number of created BacklogItem, Release, or Sprint instances, so why not just allow the collections to grow unbounded and ignore these specific modifications on Product? What additional cost would there be in keeping the large cluster aggregate? The problem is that it could actually grow out of control. Before thoroughly examining why, let's consider the most important modeling tip the team needed.
然而,尽管有清晰的事务优点,四个简单的聚合从客户使用角度不是特别方便。也许我们可以把大聚合转变一下消除并发问题。通过设置我们的Hibernate的optimistic-lock选项为false,事务失败的多米诺影响就会消除。那么就没有对创建BacklogItem, Release或Sprint实例数量的不变性约束,所以为什么不干脆允许集合无限增加,并忽略产品(Product)上的这些修改规范?这里会有什么其他的代价来维护一个大的聚合?其实问题是它实时上可能会失控的增长。在彻底的调查为什么前,让我们考虑团队需要的最重要的建模小建议。
规则:为真实的不变性在一致性边界内建模(Rule: Model True Invariants In Consistency Boundaries)
When trying to discover the aggregates in a bounded context, we must understand the model's true invariants. Only with that knowledge can we determine which objects should be clustered into a given aggregate.
当在界限上下文试着发现聚合时,我们必须理解模型的真实不变性。只有了解这些我们才能决定那个对象应该被聚类到指定的聚合。
An invariant is a business rule that must always be consistent. There are different kinds of consistency. One is trans- actional, which is considered immediate and atomic. There is also eventual consistency. When discussing invariants, we are referring to transactional consistency. We might have the invariant:
c = a + b
不变性是一个必须始终保持一致的逻辑规则。有很多不同类型的一致性。一种是被认为立即和原子的事务性。还有一种最终一致性。当讨论不变性,我们参考事务一致性。我们可能有如下的不变性:
c = a + b
Therefore, when a is 2 and b is 3, c must be 5. According to that rule and conditions, if c is anything but 5, a system invariant is violated. To ensure that c is consistent, we model a boundary around these specific attributes of the model:
所以,当a是2,b是3时,c必须为5.依据这条规则和条件,如果c是一个非5的结果,就违反了这个系统的不变性。为保证c是一致的,我们会在模型的这个规范属性的边界建模。
1 | AggregateType1 { |
The consistency boundary logically asserts that everything inside adheres to a specific set of business invariant rules no matter what operations are performed. The consistency of everything outside this boundary is irrelevant to the aggregate. Thus, aggregate is synonymous with transactional consistency boundary. (In this limited example, AggregateType1 has three attributes of type int, but any given aggregate could hold attributes of various types.)
一致性边界逻辑上维护它内部所有内容,遵守业务不变规则的规范集,无论对它做任何操作。在这个界限外部的其他的一致性都和这个聚合无关。因此,聚合是事务一致性边界的同义词。(在这个有限的示例中,AggregateType1有三个int类型的属性,但聚合可能包含任何类型的属性。)
When employing a typical persistence mechanism we use a single transaction to manage consistency. When the transaction commits, everything inside one boundary must be consistent. A properly designed aggregate is one that can be modified in any way required by the business with its invariants completely consistent within a single transaction. And a properly designed bounded context modifies only one aggregate instance per transaction in all cases. What is more, we cannot correctly reason on aggregate design without applying transactional analysis.
当采用一个典型的持久化机制时,我们通常使用一个事务来管理一致性。当事务提交,一个界限内的所有内容必须一致。一个恰当设计的聚合,无论业务请求如何修改都可以在一个事务对象中保证它的不变性完整一致。并且,一个恰当设计的界限上下文所有情况下,应该仅在一个事务中修改一个聚合实例。另外,我们没有合理的理由,在没有经过事务分析,就去设计聚合。
Limiting the modification of one aggregate instance per transaction may sound overly strict. However, it is a rule of thumb and should be the goal in most cases. It addresses the very reason to use aggregates.
限制一个事务修改一个聚合实例听起来有点过分严格。然而,这是首要的规则,并且应该是大部分场景的目标。它定位了使用聚合的非常重要的原因。
Since aggregates must be designed with a consistency focus, it implies that the user interface should concentrate each request to execute a single command on just one aggregate instance. If user requests try to accomplish too much, it will force the application to modify multiple instances at once.
因为聚合必须设计为聚焦一致性,它暗示用户接口应该集中每个请求仅在一个聚合实例上执行。如果用户请求试图完成更多内容,它将会强制应用一次修改多个实例。
Therefore, aggregates are chiefly about consistency boundaries and not driven by a desire to design object graphs. Some real-world invariants will be more complex than this. Even so, typically invariants will be less demanding on our modeling efforts, making it possible to design small aggregates.
因此,聚合设计主要是考虑一致性边界,而非是设计对象图驱动。一些显示世界的不变性会这些更加复杂。尽管如此,在我们建模时典型的不变性将会不在吃力,这也使得设计小的聚合成为可能。
规则: 设计小聚合(Rule: Design Small Aggregates)
We can now thoroughly address the question: What additional cost would there be in keeping the large cluster aggregate? Even if we guarantee that every transaction would succeed, we still limit performance and scalability. As our company develops its market, it's going to bring in lots of tenants. As each tenant makes a deep commitment to ProjectOvation, they'll host more and more projects and the management artifacts to go along with them. That will result in vast numbers of products, backlog items, releases, sprints, and others. Performance and scalability are nonfunctional requirements that cannot be ignored.
我们现在可以彻底的定位问题:保持大的聚合对象会有哪些额外的代价?即使我们保证每一个事务都成功,我们还限制了性能和扩展性。随着我们的公司开拓市场,它开始引入很多的租户。随着每个租户在ProjectOvation上做深度托付,他们将会寄付更多的项目并管理相应资料。这会造成很多products, backlog items, releases, sprints等等。性能和扩展性是不可忽视的非功能性需求。
Keeping performance and scalability in mind, what happens when one user of one tenant wants to add a single backlog item to a product, one that is years old and already has thousands of backlog items? Assume a persistence mechanism capable of lazy loading (Hibernate). We almost never load all backlog items, releases, and sprints all at once. Still, thousands of backlog items would be loaded into memory just to add one new element to the already large collection. It's worse if a persistence mechanism does not support lazy loading. Even being memory conscious, sometimes we would have to load multiple collections, such as when scheduling a backlog item for release or committing one to a sprint; all backlog items, and either all releases or all sprints, would be loaded.
牢记性能和扩展性,当一个租户的一个用户想要为产品(Product)添加单个需求积压(backlog item),或另一个已经有一年时间包含上千个需求积压的产品会发生什么?
假设一个持久化机制有延迟加载的能力(Hibernate)。我们可能从来不会一次加载所有的需求积压(backlog item),releases和sprints。然而,上千的需求积压(backlog item)仍然会因为要往已经存在的集合中添加一个元素而加载所有元素到内存。如果持久化机制不支持延迟加载问题会更糟。即使意识到内存问题,有时我们将会不得不加载多个集合,例如当为版本(release)规划一个需求积压(backlog item),或者提交到冲刺;所有的需求积压项(backlog item),和其他的所有版本(release)或者所有的冲刺(sprints),都将被加载。
To see this clearly, look at the diagram in Figure 3 containing the zoomed composition. Don't let the 0..* fool you; the number of associations will almost never be zero and will keep growing over time. We would likely need to load thousands and thousands of objects into memory all at once, just to carry out what should be a relatively basic operation. That's just for a single team member of a single tenant on a single product. We have to keep in mind that this could happen all at once with hundreds and thousands of tenants, each with multiple teams and many products. And over time the situation will only become worse.
为清晰的看到这些,看下面的图表3中的图解,包含聚焦的组合。不要让0..*迷惑到;关联的数量机会不会为0,并且会随着时间不断的增长。我们可能需要一次加载成千成千的对象到内存中,仅仅为带出一个相关的基本操作。这还仅仅是单个租户的一个团队成员操作一个产品。我们需要牢记这些会在成百上千个租户中发生,每一个都有多个团队,很多的产品。随着时间增加情况只会变的更糟。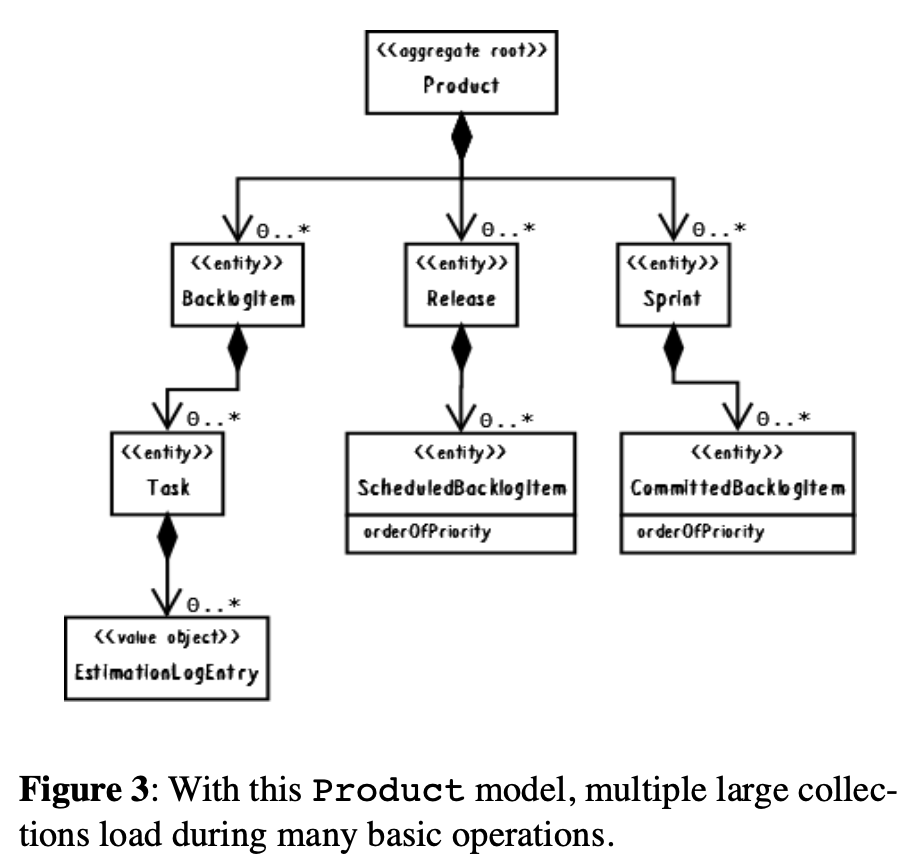
This large cluster aggregate will never perform or scale well. It is more likely to become a nightmare leading only to failure. It was deficient from the start because the false invariants and a desire for compositional convenience drove the design, to the detriment of transactional success, performance, and scalability.
大群类聚合不会有很好的性能和扩展。更可能会变成一个只会失败的噩梦。它从开始就是有缺陷的,因为错误的不变性和苛求组合的方便性作为设计驱动,损害了事务成功率,性能和可扩展能力。
If we are going to design small aggregates, what does “small” mean? The extreme would be an aggregate with only its globally unique identity and one additional attribute, which is not what's being recommended (unless that is truly what one specific aggregate requires). Rather, limit the aggregate to just the root entity and a minimal number of attributes and/or value-typed properties. The correct minimum is the ones necessary, and no more.
如果我们打算设计小的聚合,那么怎么算”小“?极端的情况,聚合仅仅包含它的全局以为标识和一个附加的属性,这不是我们推荐的(除非这是真实的一个聚合规则需要的)。宁愿,限制聚合仅仅包含根实体和最小数量的属性和值类型属性。正确的最小部分才是真正需要的,不要包含其他的。
Which ones are necessary? The simple answer is: those that must be consistent with others, even if domain experts don't specify them as rules. For example, Product has name and description attributes. We can't imagine name and description being inconsistent, modeled in separate aggregates. When you change the name you probably also change the description. If you change one and not the other, it's probably because you are fixing a spelling error or making the description more fitting to the name. Even though domain experts will probably not think of this as an explicit business rule, it is an implicit one.
那些是需要的?简单的答案是:那些必须和其他内容保持一致性的,即使领域专家也不能用规则阐述他们。例如,Product有name和description属性。我们无法想象name和description变的不一致,建模到了分开的聚合中。当你修改name你很可能同时修改了description。如果你修改了一个而不修改另一个,这可能因为你正在修正一个拼写错误,或者使描述更加适合name。尽管如此领域专家通常不会把这些当做显式的业务规则,这是一个隐式规则。
What if you think you should model a contained part as an entity? First ask whether that part must itself change over time, or whether it can be completely replaced when change is necessary. If instances can be completely replaced, it points to the use of a value object rather than an entity. At times entity parts are necessary. Yet, if we run through this exercise on a case-by-case basis, many concepts modeled as entities can be refactored to value ob- jects. Favoring value types as aggregate parts doesn't mean the aggregate is immutable since the root entity itself mutates when one of its value-typed properties is replaced.
如果你认为你应该为一个被包含的部分建模创建一个实体(entity)将会怎样?首先来问为何这一部分必须独立修改,或者当需要修改时它是否可以被全量的替换。如果实例可以被完整的替换,这表明应该使用值对象(value object)而非实体(entity)。当需要使用实体(entity)时,一样,如果我们一个一个的去走完这个流程,很多被建模为实体的概念可以被重构为值对象。聚合中有用的值类型不是说聚合时不可变的,因为根实体本身在它的值类型属性被替换时也发生了变化。
There are important advantages to limiting internal parts to values. Depending on your persistence mechanism, values can be serialized with the root entity, whereas entities usu- ally require separately tracked storage. Overhead is higher with entity parts, as, for example, when SQL joins are ne- cessary to read them using Hibernate. Reading a single database table row is much faster. Value objects are smaller and safer to use (fewer bugs). Due to immutability it is easier for unit tests to prove their correctness.
限制内部部分为值有重要的优点。依赖你的持久化机制,值可以随着根实体(entiry)被序列化,然后实体(entity)通常需要单独的存储。实体(entity)部分开销是更高的,因为,例如,当使用Hibernate需要SQL join来读取他们的时候。读取单独的数据库表记录是更快的。值对象更小,并且更安全使用(更少bug)。由于不可变性它更容易单元测试来验证它们的正确性。
On one project for the financial derivatives sector using [Qi4j], Niclas [Hedhman] reported that his team was able to design approximately 70% of all aggregates with just a root entity containing some value-typed properties. The re- maining 30% had just two to three total entities. This doesn't indicate that all domain models will have a 70/30 split. It does indicate that a high percentage of aggregates can be limited to a single entity, the root.
在一个使用[Qi4j]的金融衍生品部门的项目,Niclas [Hedhman]报告他的团队可以使用一个根实体包含一些值类型属性,设计接近70%的聚合,剩下的30%仅仅包含两三个实体。这并不是表明所有的领域模型都是7/3划分。它只是表明大部分的聚合可以限制到了一个实体,根实体。
The [DDD] discussion of aggregates gives an example where multiple entities makes sense. A purchase order is assigned a maximum allowable total, and the sum of all line items must not surpass the total. The rule becomes tricky to enforce when multiple users simultaneously add line items. Any one addition is not permitted to exceed the limit, but concurrent additions by multiple users could collectively do so. I won't repeat the solution here, but I want to emphasize that most of the time the invariants of business models are simpler to manage than that example. Recognizing this helps us to model aggregates with as few properties as pos- sible.
[DDD]聚合的讨论给了一个包含多个实体的有意义的例子。一个购买订单被指定了一个最大允许数量,那么所有购买项的汇总数量必须不能超过总数。当多个用户同时添加购买项这个规则会变的棘手。任何一个添加都不允许超过限制,但当多个用户并发添加可能共同的做这个事情。我不想在这里重复解决方案,但我想强调大部分时间业务的不变性模型是比这个例子更容易管理的。认识到这点有助于我们使用尽可能少的属性来为聚合建模。
Smaller aggregates not only perform and scale better, they are also biased toward transactional success, meaning that conflicts preventing a commit are rare. This makes a system more usable. Your domain will not often have true invariant constraints that force you into large composition design situations. Therefore, it is just plain smart to limit aggregate size. When you occasionally encounter a true consist- ency rule, then add another few entities, or possibly a col- lection, as necessary, but continue to push yourself to keep the overall size as small as possible.
更小的聚合不仅仅性能和扩展性更好,它们也更有助于事务成功,意味着提交是冲突拒绝更少。这使得系统更有用。你的领域通常不会有真实的不变性约束,强制你进入大面积的组合设计场景。因此,就明智的限制聚合的大小。当你偶尔面临一个真实的约束规则,然后添加了其他的一些实体,或者也可能是需要集合,但是请继续让自己总体上保持尽可能的小。
不要相信所有用例(Don’t Trust Every Use Case)
Business analysts play an important role in delivering use case specifications. Since much work goes into a large and detailed specification, it will affect many of our design decisions. Yet, we mustn't forget that use cases derived in this way does not carry the perspective of the domain experts and developers of our close-knit modeling team. We still must reconcile each use case with our current model and design, including our decisions about aggregates. A common issue that arises is a particular use case that calls for the modification of multiple aggregate instances. In such a case we must determine whether the specified large user goal is spread across multiple persistence transactions, or if it occurs within just one. If it is the latter, it pays to be skeptical. No matter how well it is written, such a use case may not accurately reflect the true aggregates of our model.
业务分析在交付用例规范中扮演了重要的角色。因为很多工作都会进入大的详细的规范,它会影响我们很多的设计决策。然而,我们必须不能忘记这种方式衍生的用例,并没有携带领域专家和开发者这些核心建模团队的视角信息。我们依然必须为我们现有的模型和设计调和每一个用例,包括我们的聚合设计。一个常见风险是一次调用修改多个聚合实例的特殊用例。这种情况我们必须决定,是否详细说明大的用户目标是跨多持久化事务的传播,或者仅仅出现在一个内部。如果是后者,那么它是存疑的。无论它是如何写的,这种用例可能不会真正影响我们模型的真实聚合。
Assuming your aggregate boundaries are aligned with real business constraints, then it's going to cause problems if business analysts specify what you see in Figure 4. Thinking through the various commit order permutations, you'll see that there are cases where two of the three requests will fail. What does attempting this indicate about your design? The answer to that question may lead to a deeper understanding of the domain. Trying to keep multiple aggregate instances consistent may be telling you that your team has missed an invariant. You may end up folding the multiple aggregates into one new concept with a new name in order to address the newly recognized business rule. (And, of course, it might be only parts of the old aggregates that get rolled into the new one.)
假设你的聚合边界与真实的业务约束对齐,如果业务分析阐述了入下图4看到的情况也将会造成问题。考虑多个提交顺序互换,你将会看到有些情况三个请求中的两个将会失败。你的设计应该如何去尝试解决?这个问题的答案会使你更深入的理解领域。试图保持多个聚合实例一致可能让你明白,你的团队丢掉了一个不变性。你可能最终会为了放置新识别的业务规则,而打包多个聚合到一个新的名称的概念中。(当然,也可能仅仅是旧的聚合的一部分改为了一个新的。)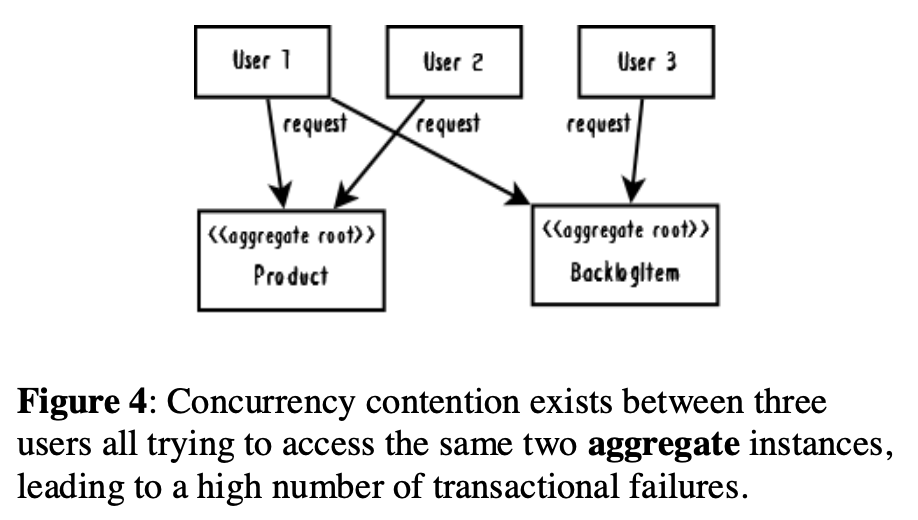
So a new use case may lead to insights that push us to remodel the aggregate, but be skeptical here, too. Forming one aggregate from multiple ones may drive out a completely new concept with a new name, yet if modeling this new concept leads you toward designing a large cluster aggregate, that can end up with all the problems of large aggregates. What different approach may help?
所以,一个新的用例可能让我们洞察到需要重新对聚合建模,但这里也是存疑的。从多个聚合形成单个可能不用提出一个全新概念,然而,如果为这个新概念建模会导致你走向设计一个大聚集的聚合,结果带来了大聚合的所有问题。有没有其他有效的途径?
Just because you are given a use case that calls for maintaining consistency in a single transaction doesn't mean you should do that. Often, in such cases, the business goal can be achieved with eventual consistency between aggregates. The team should critically examine the use cases and challenge their assumptions, especially when following them as written would lead to unwieldy designs. The team may have to rewrite the use case (or at least re-imagine it if they face an uncooperative business analyst). The new use case would specify eventual consistency and the acceptable update delay. This is one of the issues taken up in Part II of this essay.
仅仅因为提供了一个在单个事务保持一致性的用例并不意味着你应该这样做。通常,这种情况,业务目标可以通过多个聚合的最终一致性达到。团队应该严格检查用例,挑战一些假设,特别是当遵从用例所写将会造成笨重的设计时。团队可能不得不重写用例(或至少重新猜想它,如果他们面临不配合的业务分析)。新的用例将会阐述最终一致性和可接受的更新延迟。这将是本系列第二部分主要研究的一个问题。
第二部分预告(Coming in Part II)
Part I has focused on the design of a number of small aggregates and their internals. There will be cases that require references and consistency between aggregates, especially when we keep aggregates small. Part II of this essay covers how aggregates reference other aggregates as well as eventual consistency.
第一部分聚焦在设计几个小的聚合和他们的内部交互。这将会是在多个聚合中使用引用和一致性的例子,特别当我们需要保持聚合足够小时。论文的第二部分覆盖如何使聚合引用其他聚合,以及最终一致性。
致谢(Acknowledgments)
Eric Evans and Paul Rayner did several detailed reviews of this essay. I also received feedback from Udi Dahan, Greg Young, Jimmy Nilsson, Niclas Hedhman, and Rickard Öberg.
引用(References)
[CQS] Martin Fowler explains Bertrand Meyer's Command-Query Separation: http://martinfowler.com/bliki/ CommandQuerySeparation.html
[DDD] Eric Evans; Domain-Driven Design—Tackling Complexity in the Heart of Software; 2003, Addison- Wesley, ISBN 0-321-12521-5.
[Hedhman] Niclas Hedhman; http://www.jroller.com/niclas/
[Qi4j] Rickard Öberg, Niclas Hedhman; Qi4j framework; http://qi4j.org/
个人经历(Biography)
Vaughn Vernon is a veteran consultant, providing architecture, development, mentoring, and training services.
This three-part essay is based on his upcoming book on implementing domain-driven design.
His QCon San Francisco 2010 presentation on context mapping is available on the DDD Community site:
http://dddcommunity.org/library/vernon_2010.
Vaughn blogs here: http://vaughnvernon.co/;
you can reach him by email here: vvernon@shiftmethod.com;
and follow him on Twitter here: @VaughnVernon