
1. 前言
flink glossary是官网上的flink概念词汇解释,里面有文档中大量名称名词的汇总解释。
文档已经很全面,当然本文不只是一个翻译。本文会借助一个例子,并通过静态代码、运行态、物理集群三条主线串讲flink的主要词汇。看完本文,你将能看懂flink作业的Logical Graph、Job Graph和Slot Graph;同时,就能全面的理解“flink跑起来是什么样子”,这非常有助于新人学习flink,再去看flink的其他文档,将会更好理解。
2. 静态代码维度
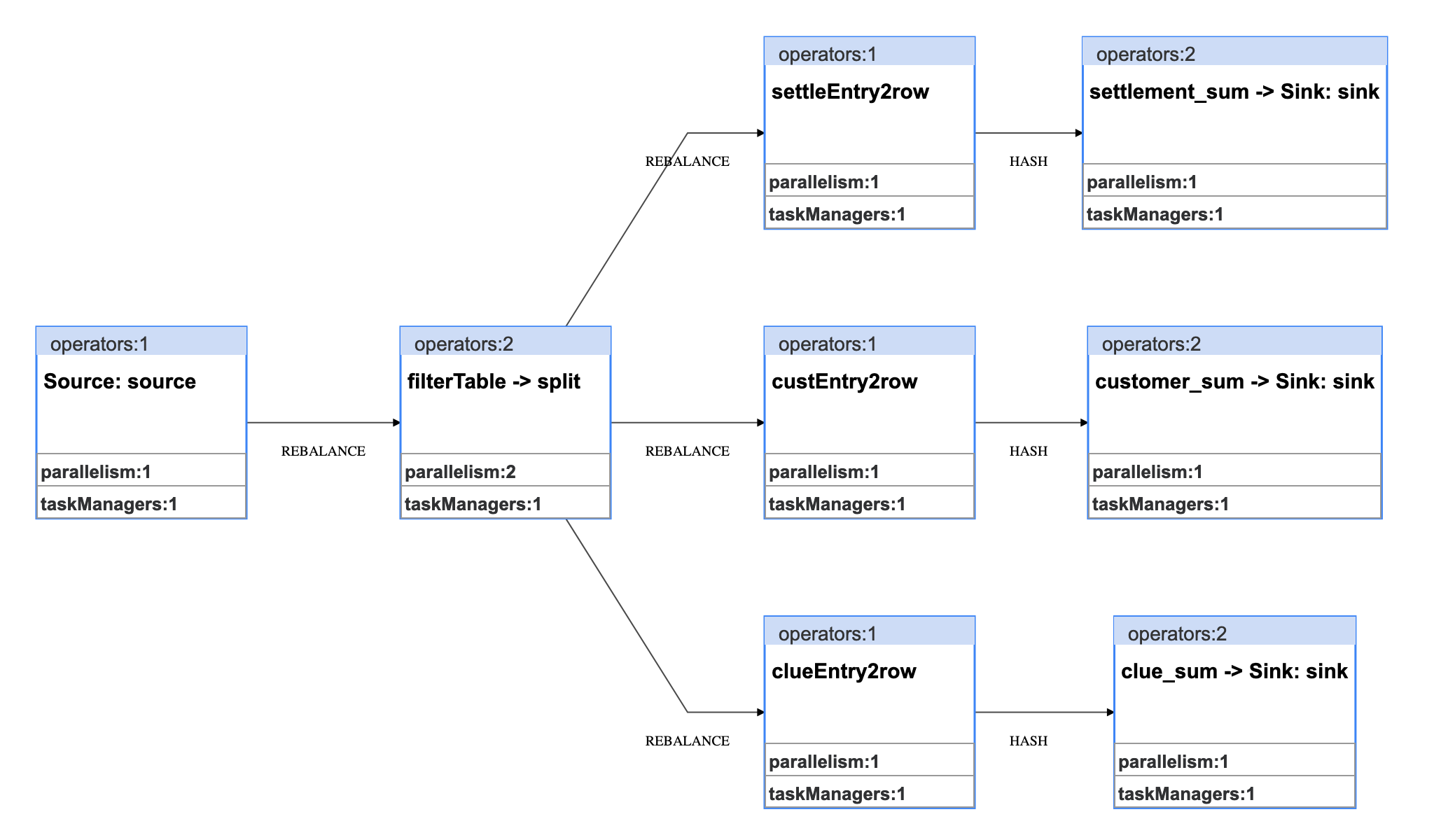
上图是一个逻辑拓扑图,它是一个有向图,基本上和编写的代码是一一对应的,是我们处理业务数据的整体处理步骤逻辑。
下面我们就从代码的维度,以程序的入口为切入点,详细的介绍相关概念。那么第一个就是flink应用。
Flink Application(flink应用)
一个Flink Application是一个提交了一个或者多个Flink作业(job)的Java应用程序。
这里着重注意,我们的一个flink应用是可以提交多个job的,也就是可以提交多个逻辑拓扑。
Flink Job(flink作业)
Flink Job是一个数据处理逻辑拓扑(logical graph)的运行时形态。通常我们代码中调用env.execute()函数就会创建一个job。
job不属于静态代码维度,这里主要是为了衔接各个概念。
logical graph(逻辑拓扑)
logical graph是一个由算子(Operator)为节点,数据流向为边组成的有向图。有时也会被称为dataflow graph。上面说了基本上和编写的代码是一一对应的,我们的代码就是定义一个个的算子和上下游关系并行度等。
Operator(算子)
算子是逻辑拓扑的节点,一个算子一般只执行一个单一的职能,通常有一个Function的实现。Source和Sink是特殊的算子,用来提取和吐出数据。
Function(函数)
函数是有开发人员实现的封装了具体应用逻辑的程序代码。大部分的函数都是由不同类型算子包装的。
Operator Chain(算子链)
算子链,是有两个或者多个不包含重分区(without repartitioning)算子组成。在同一个算子链中的算子之间可以直接传递数据,而不需要序列化和网络传输。
上面这几个词汇基本上就是我们编写代码的主要内容,我这里姑且都称为静态词汇,突出它们都是可以从我们代码描述中可以直接看的到的内容。
3. 运行态维度
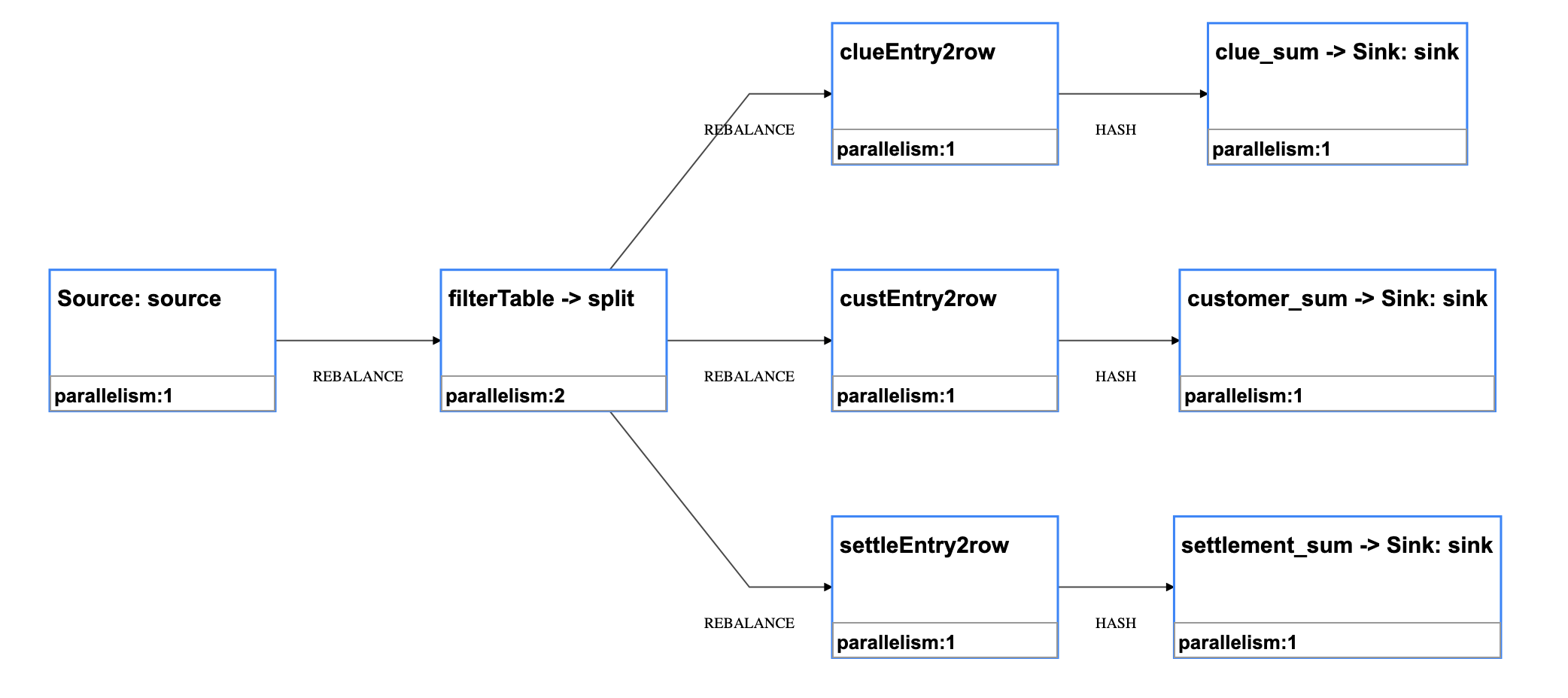
上图是一个Job Graph的图,也称为Physical Graph. 可以认为是flink应用程序运行时的形态。
Physical Graph(物理拓扑)
一个物理拓扑是对应逻辑拓扑在分布式运行时运行后转换结果。节点是Task(任务),边表明了数据流的流入、流出关系。
Task(任务)
Task是物理拓扑的节点,是flink运行时执行的基本单元。具体来说,Task封装的是算子或者算子链的一个parallel instance(并行实例)。这里也能说明,为什么上面介绍算子链的时候说,算子链里面的算子直接传递数据时,不需要序列化和网络传输,因为他们运行时肯定在同一个task manager的同一个线程中。
Sub Task(子任务)
子任务是任务的一个处理特定分区数据的并行实例。这里仅仅是用来强调任务的并行性,只是描述性用语。
上面的三个概念就是物理拓扑的主要组成部分,大家可以照着这些概念再看一下上面的物理拓扑图,特别是和静态层面概念对应一下,就能更好的理解代码。
4. 物理集群维度
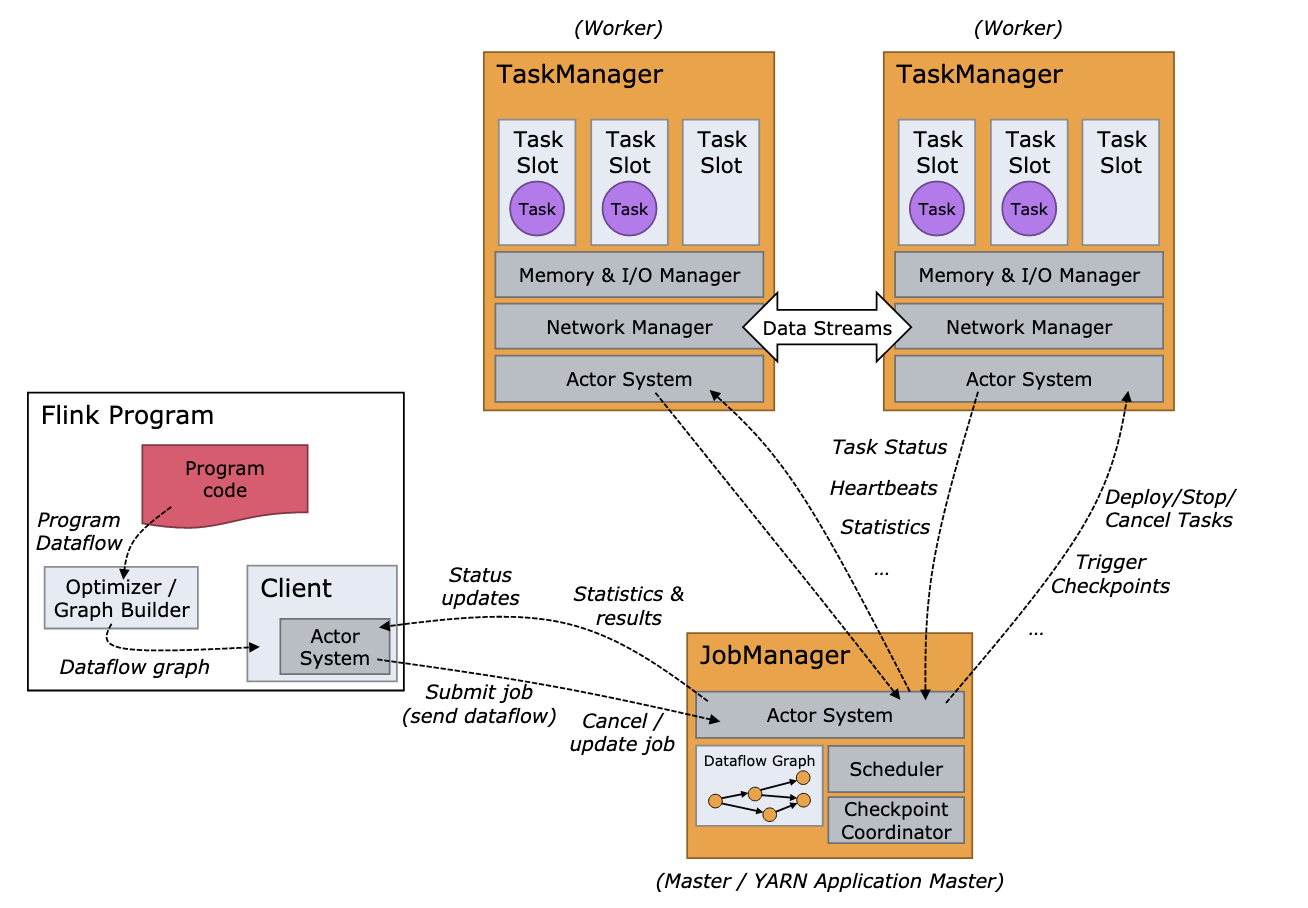

上图1是flink集群的架构图,标明了集群的物理组成架构。
图2是本文例子的task slot graph(任务槽分布图)。
下面,我们对着flink架构图来阐述flink集群的主要词汇概念。
JobManager(作业管理器)
作业管理器是Flink集群的协调器,用来调度资源、任务和状态管理等。Jobmanager主要有三个独立的组件组成:Flink Resource Manager(资源管理器), Flink Dispatcher(分发器) 和Flink JobMaster(每个作业一个)。
Flink JobMaster
主要用来监控一个具体作业的所有任务的运行情况,并在合适的时间执行状态持久化和Task的重新调度。
TaskManager(任务管理器)
TaskManager是flink集群的工作进程,Task会被调度到具体的TaskManager来执行。TaskManager之间会彼此通讯来交换任务处理中的数据。每个TaskManager会有规划数量的Task Slot,用来表明这工作进程可以调度的资源数量。
Task Slot(任务槽)
一个Task Slot任务槽,可以用来执行一个Task,是flink进群资源调度管理的基本单位。
5. flink为我们提供了什么?
至此,本文从flink的静态代码维度、运行态维度、物理集群维度对flink做了整体的阐述,相信大家已经有了一个整体的了解。
试想,我们编写的代码,大部分也都是对于来数的一个加工处理,就好比工厂流水线的来件加工,不断的把物料处理为我们想要的样子。
那么为什么还有流式编程的概念?为什么冒出了那么多的流式编程的框架storm、spark、flink等等?流式编程框架为我们提供了什么?
笔者有幸在项目中使用过storm和flink,这里个人见解总结了几点,不对之处欢迎评论区讨论。
个人认为流式框架给我们提供了如下能力:
- 并发模板。
试想如果我们自己去编写接入数据、处理数据、吐出数据的代码。在处理大并发场景,那么我们需要编写大量的并发代码,不同处理阶段,时间复杂度不同,需要抽象封装处理模板,并提供不同的并行度。流式编程框架通常为我们提供了完善的编程模型,并且可以灵活的配置不同处理阶段的并行度。 - 流程编排。
流式框架在提供了并发编程模型的同时,也提供了算子的编排能力,借助流式编程,我们通常可以根据业务需要编排数据处理的流水线,计算粒度细化,灵活性大大增强,代码的共用性也相应的提高。 - 集群资源管理、任务调度。
如果我们自己来编写数据处理,通常仅能局限于单个jvm进程。而流式编程框架为我们提供了集群的能力,可以在集群内调度更多的资源,提供更高的并行度和性能。 - 任务监控。
无论storm还是flink都为开发者提供了控制台,可以监控整个任务的调度日志和数据流量监控,这也是非常重要的一个部分。
从使用来看,flink、storm这些流式框架,简单的就像是一个小工具。但从企业角度看,他们提供了大数据量、无尽数据的实时编程方案,包括平台集群、资源调度、作业、任务等等。
6. 参考资料
flink官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/concepts/glossary/